















")







Alfa dog evolution: Self Study 3 days 100:0 rolling Li Shishi version of the old dog
chinatopwin
chinatopwin
2017-10-19 09:55:03
London local time at 18:00 on October 18th (Beijing time 19 01:00), AlphaGo again on the world's
top scientific journal Nature. "
More than a year ago, AlphaGo is a cover article in the period January 28, 2016, Deepmind
More than a year ago, AlphaGo is a cover article in the period January 28, 2016, Deepmind
issued a heavy paper, introduced this beat the European Championship Chess fan Hui artificial
intelligence program.
In May this year, the score of 3:0 to win the Chinese player kija, AlphaGo announced his
In May this year, the score of 3:0 to win the Chinese player kija, AlphaGo announced his
retirement, but DeepMind did not stop the pace of research. London local time on October 18th,
the DeepMind team announced the strongest version of AlphaGo, codenamed AlphaGo Zero. its
unique cheats, is "self self-taught". Moreover, from the beginning of a white paper, zero based
learning, in just 3 days, becoming the top master.
The team said, before AlphaGo Zero has exceeded the level of all versions of AlphaGo. have won
The team said, before AlphaGo Zero has exceeded the level of all versions of AlphaGo. have won
against South Korean players Li Shishi's version of AlphaGo, AlphaGo Zero 100:0 has achieved
overwhelming success.DeepMind team will research on AlphaGo Zero in the form of a paper,
published in the October 18th "Nature journal.
"Within two years AlphaGo achieved amazing. Now, AlphaGo Zero is our strongest version, it
"Within two years AlphaGo achieved amazing. Now, AlphaGo Zero is our strongest version, it
raises a lot of.Zero to improve the computational efficiency, and not to use any data of human
chess," the father of the AlphaGo, DeepMind co-founder and CEO Demes Ha Sabis (Demis
Hassabis) said, "in the end, we want to use it the algorithm of breakthrough, to help solve real
world problems urgent, such as protein folding or design new materials. If we AlphaGo, can
make progress on these issues, it has the potential to promote the understanding of life, and in a
positive way to affect our lives"
No longer limited by human knowledge, only 4 TPU
AlphaGo the previous version, with millions of human experts go chess, and strengthen the
In addition to the above differences, AlphaGo Zero in 3 aspects compared with the previous
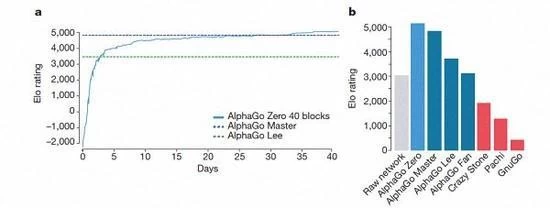
AlphaGo several versions of the rankings
According to Kazakhstan Biscay and Silva introduction, these different help version of AlphaGo
AlphaGo the previous version, with millions of human experts go chess, and strengthen the
supervision of learning of self training.
Before defeating the professional player of the go, it went through months of training, relying on
Before defeating the professional player of the go, it went through months of training, relying on
multiple machines and 48 TPU (Google chips designed to speed up deep Neural Network
Computing)
AlphaGo Zero is a qualitative improvement on this basis. The biggest difference is that it is no
AlphaGo Zero is a qualitative improvement on this basis. The biggest difference is that it is no
longer necessary to human data. That is to say, it has no contact with human chess. R & D
team just let it free to play chess on the board, and then self game. It is worth mentioning that
AlphaGo Zero is a "low carbon", to use a machine and 4 TPU, greatly saves resources.
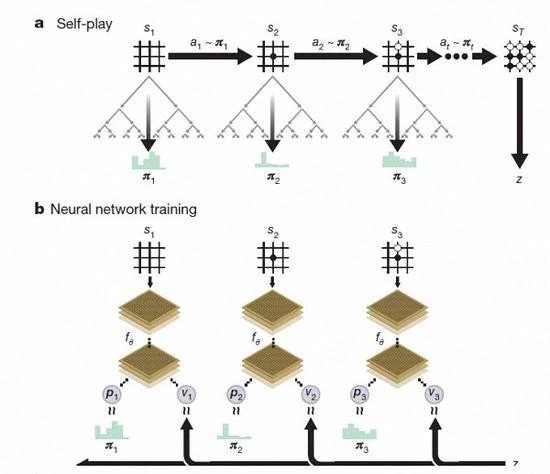
AlphaGo Zero reinforcement learning under the self play chess
After a few days of training, AlphaGo Zero completed nearly 5 million disc self game, can go
AlphaGo Zero reinforcement learning under the self play chess
After a few days of training, AlphaGo Zero completed nearly 5 million disc self game, can go
beyond the human, and defeated all previous versions of the AlphaGo.DeepMind team said on
the official blog, with the updated neural network and search algorithms of recombinant Zero, as
the training deepens, the performance of the system a little bit in self progress. The game
results are getting better and better, at the same time, neural network is more accurate.
The process of acquiring knowledge by AlphaGo Zero
"The reason these technical details are stronger than the previous version, we no longer have
"The reason these technical details are stronger than the previous version, we no longer have
the limits of human knowledge, it can learn to AlphaGo its highest players go field." AlphaGo
team leader David Silva (Dave Sliver) said.
According to David Silva introduction, AlphaGo Zero uses the new reinforcement learning
According to David Silva introduction, AlphaGo Zero uses the new reinforcement learning
method, let oneself become the teacher. Don't even know what a system to go, just from a
single neural network, the neural network search algorithm is powerful, the self playing chess.
With the increase of self game, neural network is gradually adjusted, enhance the predictive
With the increase of self game, neural network is gradually adjusted, enhance the predictive
ability of the next step, and ultimately win the game. More powerful, with in-depth training, the
DeepMind team found that AlphaGo Zero also independently discovered the rules of the game,
and out of the new strategy, bring new insights into this ancient chess round game.
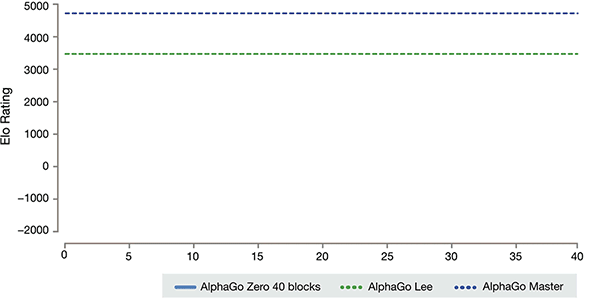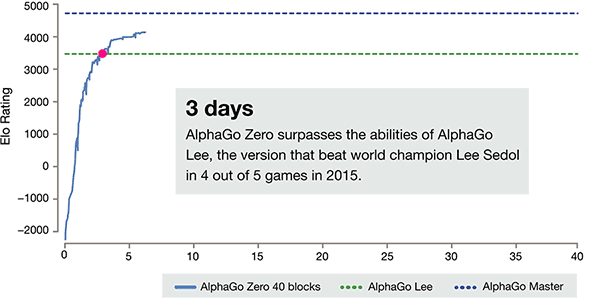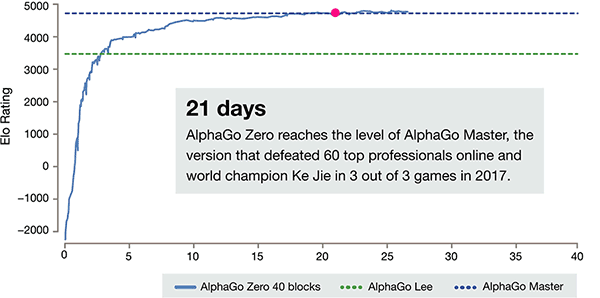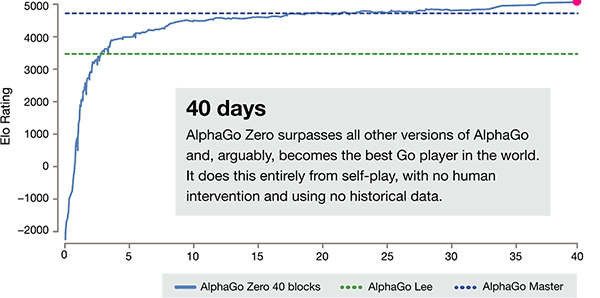
Self study for 3 days, beat the old version of AlphaGo
Self study for 3 days, beat the old version of AlphaGo
In addition to the above differences, AlphaGo Zero in 3 aspects compared with the previous
version has obvious difference
The training time axis of AlphaGo-Zero
First, AlphaGo Zero only uses black and white on the chessboard as input, while the former
The training time axis of AlphaGo-Zero
First, AlphaGo Zero only uses black and white on the chessboard as input, while the former
includes a small number of artificially designed feature inputs
Secondly, AlphaGo Zero uses only a single neural network. In previous versions, the AlphaGo
Secondly, AlphaGo Zero uses only a single neural network. In previous versions, the AlphaGo
uses the strategy of "network" to choose the next move, and the use of "value network" to
forecast each step after the winner. But in the new version, the two neural network can be made
one. It can get the training and evaluation more efficient.
Third, AlphaGo Zero does not use the fast, random walk method. In previous versions, AlphaGo
Third, AlphaGo Zero does not use the fast, random walk method. In previous versions, AlphaGo
is fast walk method to predict which game player will win the game from the current situation.
On the contrary, the new version is to rely on the high quality of the neural network to evaluate
game situation.
AlphaGo several versions of the rankings
According to Kazakhstan Biscay and Silva introduction, these different help version of AlphaGo
has improved in the system, and the change of the algorithm make the system to become
stronger and more effective.
After just 3 days of self training, AlphaGo Zero on the strong beats the previous victory over Li
Shishi in the old version of AlphaGo, they are 100:0. After 40 days of self training, AlphaGo Zero
beat AlphaGo Master version. "Master" beat the world's top players, even including kija ranked
first in the world.
To promote the progress of human society using artificial intelligence DeepMind mission, the
To promote the progress of human society using artificial intelligence DeepMind mission, the
ultimate AlphaGo didn't go, their goal has been to use AlphaGo to create a general, explore the
ultimate tools of the universe of.AlphaGo Zero's ascension, let DeepMind see a change in the
fate of mankind by using the artificial intelligence technology breakthrough. They are currently
active and the British medical institutions and power energy sector cooperation, improve the
treatment efficiency and energy efficiency.