























アルファ犬の進化: 自己研究3日100:0 ローリング李獅子バージョン旧犬の
chinatopwin
chinatopwin
2017-10-19 09:55:03
10月18日に18:00 でロンドン現地時間 (北京時間 19 01:00)、再び世界のトップの科学誌の性質に AlphaGo。"
1年以上前、AlphaGo は、期間中のカバー記事です2016、Deepmind は、重い紙を発行し、このビートヨーロッパ選手権チェスファンホイ人工知能プログラムを導入しました。
今年5月には3:0 の得点が中国選手キジャを獲得し、AlphaGo は引退を発表したが、DeepMind は研究のペースを止めなかった。ロンドン現地時間10月18日、DeepMind チームは AlphaGo、コードネーム AlphaGo ゼロの最強バージョンを発表した。そのユニークな攻略は、"自己独学" です。また、ホワイトペーパーの最初から、ゼロベースの学習は、わずか3日間で、トップマスターになる。
チームは、AlphaGo ゼロの前に、AlphaGo のすべてのバージョンのレベルを超えていると述べた。AlphaGo、AlphaGo ゼロ100:0 の韓国の選手李獅子のバージョンに対して獲得している圧倒的な成功を達成しています。DeepMind チームは、10月18日 "ネイチャージャーナルに掲載された紙の形で AlphaGo ゼロの研究を行います。
「2年以内に AlphaGo はすばらしい達成した。今、AlphaGo ゼロは私たちの最強バージョンであり、それは多くを発生させます。ゼロは、計算効率を向上させるために、人間のチェスの任意のデータを使用しないように、"AlphaGo、DeepMind 共同創業者兼 CEO Demes ハサヸビス (デメロールルーソス Hassabis) の父は、" 最終的には、我々はそれをブレークスルーのアルゴリズムを使用したい、現実世界を解決するため蛋白質の折りたたみまたは設計の新しい材料のような緊急の問題。もし我々が AlphaGo、これらの問題を進展させることができる、それは生命の理解を促進する可能性があり、肯定的な方法で私たちの生活に影響を与える "
もはや人間の知識によって制限されない、唯一の 4 TPU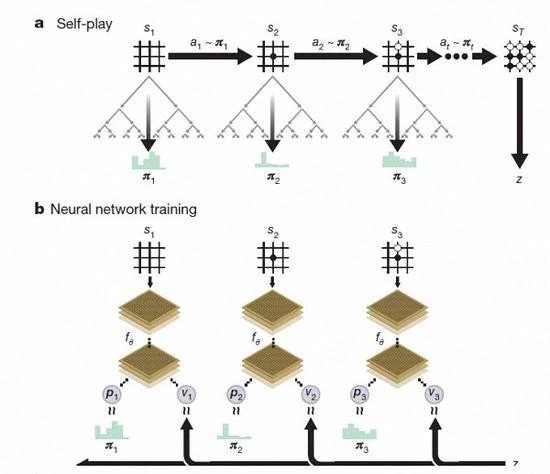
AlphaGo は、人間の専門家の数百万のチェスを行って、以前のバージョンを、自己訓練の学習の監督を強化します。
碁のプロ選手を倒す前に、それは、複数のマシンと 48 TPU (ディープニューラルネットワークコンピューティングを高速化するために設計された Google のチップ) に頼る、訓練の月を経て
AlphaGo ゼロは、この基礎の質的改善です。最大の違いは、もはや人間のデータに必要ではないということです。つまり、それは人間のチェスとの接触を持っていると言うことです。研究開発チームは、ちょうどそれがボード上のチェスを再生する自由を聞かせて、そして自己ゲーム。それは AlphaGo ゼロは "低炭素" であることを言及する価値がある、マシンと 4 TPU を使用するには、大幅にリソースを節約します。
セルフプレイチェスの AlphaGo ゼロ強化学習
トレーニングの数日後、AlphaGo ゼロは、人間を超えて行くことができるほぼ500万ディスクの自己ゲームを完了し、AlphaGo のすべての以前のバージョンを破った DeepMind チームは、更新されたニューラルネットワークとの検索アルゴリズムで、公式ブログで述べている組換えゼロは、訓練が深まるにつれて、自己の進歩で少しずつシステムのパフォーマンス。ゲームの結果が良くなっていると、同時に、ニューラルネットワークは、より正確です。
上記の違いに加えて、以前のバージョンと比較して3面で AlphaGo ゼロは明らかな違いを持っている
AlphaGo-ゼロのトレーニング時間軸
前者は人工的に設計された機能入力の数が少ないが、最初に、AlphaGo ゼロは、入力としてチェスに黒と白を使用します。
次に、AlphaGo ゼロは1つのニューラルネットワークのみを使用します。以前のバージョンでは、AlphaGo は、次の移動を選択する "ネットワーク" の戦略を使用して、勝者の後に各ステップを予測するために "バリューネットワーク" の使用。しかし、新しいバージョンでは、2つのニューラルネットワークを1つにすることができます。それは、より効率的なトレーニングと評価を得ることができます。
第三に、AlphaGo ゼロは、高速、ランダムウォーク法を使用していません。以前のバージョンでは、AlphaGo は、ゲームプレーヤーは、現在の状況からゲームに勝つかを予測するための高速ウォーク方法です。逆に、新しいバージョンは、ゲームの状況を評価するために、ニューラルネットワークの高品質に依存することです。
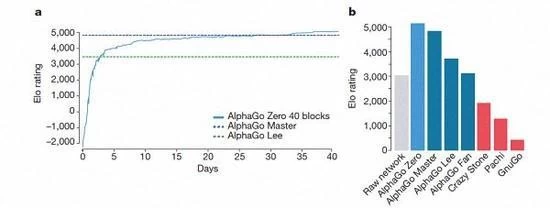
ランキングのいくつかのバージョンを AlphaGo
カザフスタンビスケーとシルバの導入によると、AlphaGo のこれらの異なるヘルプバージョンは、システムで改善されており、アルゴリズムの変更は、システムが強く、より効果的になるようになります。
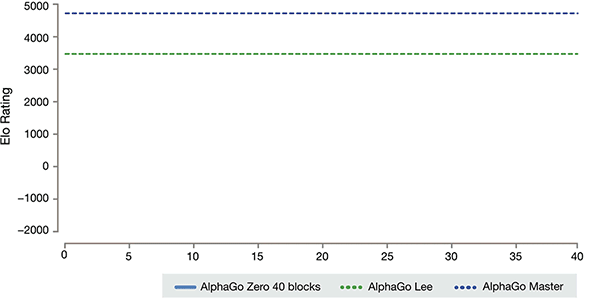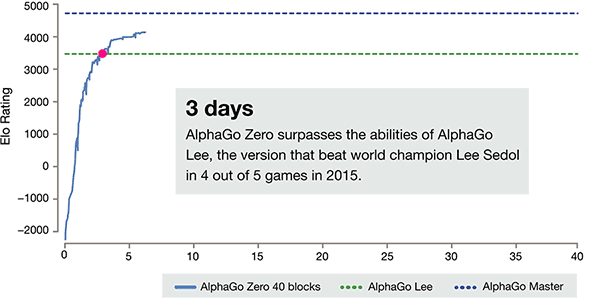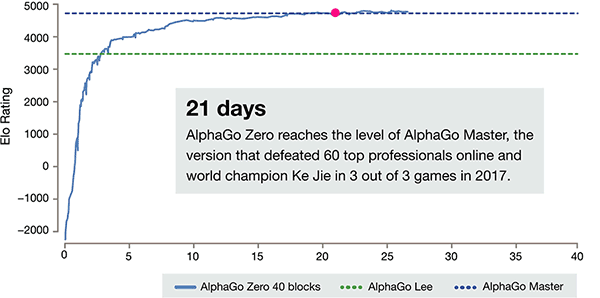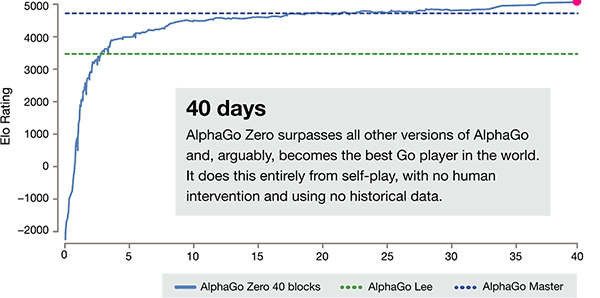
自己トレーニングのわずか3日後、強力な AlphaGo の旧バージョンで李獅子以上の前の勝利を打つ AlphaGo ゼロ、彼らは100:0 です。セルフトレーニングの40日後、AlphaGo ゼロビート AlphaGo マスターバージョン。世界で初めてランクインしたキジャも含め、世界トップの選手を「名人」が破った。
人工知能 DeepMind ミッションを使用して人間社会の進歩を促進するために、究極の AlphaGo は行かなかった、彼らの目標は、一般的なを作成する AlphaGo を使用して、の宇宙の究極のツールを探るされています。AlphaGo ゼロの昇天、DeepMind は、人工知能技術のブレークスルーを使用して、人類の運命の変化を見てみましょう。彼らは現在、英国の医療機関や電力エネルギーセクターの協力、治療効率とエネルギー効率を向上させるアクティブです。
1年以上前、AlphaGo は、期間中のカバー記事です2016、Deepmind は、重い紙を発行し、このビートヨーロッパ選手権チェスファンホイ人工知能プログラムを導入しました。
今年5月には3:0 の得点が中国選手キジャを獲得し、AlphaGo は引退を発表したが、DeepMind は研究のペースを止めなかった。ロンドン現地時間10月18日、DeepMind チームは AlphaGo、コードネーム AlphaGo ゼロの最強バージョンを発表した。そのユニークな攻略は、"自己独学" です。また、ホワイトペーパーの最初から、ゼロベースの学習は、わずか3日間で、トップマスターになる。
チームは、AlphaGo ゼロの前に、AlphaGo のすべてのバージョンのレベルを超えていると述べた。AlphaGo、AlphaGo ゼロ100:0 の韓国の選手李獅子のバージョンに対して獲得している圧倒的な成功を達成しています。DeepMind チームは、10月18日 "ネイチャージャーナルに掲載された紙の形で AlphaGo ゼロの研究を行います。
「2年以内に AlphaGo はすばらしい達成した。今、AlphaGo ゼロは私たちの最強バージョンであり、それは多くを発生させます。ゼロは、計算効率を向上させるために、人間のチェスの任意のデータを使用しないように、"AlphaGo、DeepMind 共同創業者兼 CEO Demes ハサヸビス (デメロールルーソス Hassabis) の父は、" 最終的には、我々はそれをブレークスルーのアルゴリズムを使用したい、現実世界を解決するため蛋白質の折りたたみまたは設計の新しい材料のような緊急の問題。もし我々が AlphaGo、これらの問題を進展させることができる、それは生命の理解を促進する可能性があり、肯定的な方法で私たちの生活に影響を与える "
もはや人間の知識によって制限されない、唯一の 4 TPU
AlphaGo は、人間の専門家の数百万のチェスを行って、以前のバージョンを、自己訓練の学習の監督を強化します。
碁のプロ選手を倒す前に、それは、複数のマシンと 48 TPU (ディープニューラルネットワークコンピューティングを高速化するために設計された Google のチップ) に頼る、訓練の月を経て
AlphaGo ゼロは、この基礎の質的改善です。最大の違いは、もはや人間のデータに必要ではないということです。つまり、それは人間のチェスとの接触を持っていると言うことです。研究開発チームは、ちょうどそれがボード上のチェスを再生する自由を聞かせて、そして自己ゲーム。それは AlphaGo ゼロは "低炭素" であることを言及する価値がある、マシンと 4 TPU を使用するには、大幅にリソースを節約します。
セルフプレイチェスの AlphaGo ゼロ強化学習
トレーニングの数日後、AlphaGo ゼロは、人間を超えて行くことができるほぼ500万ディスクの自己ゲームを完了し、AlphaGo のすべての以前のバージョンを破った DeepMind チームは、更新されたニューラルネットワークとの検索アルゴリズムで、公式ブログで述べている組換えゼロは、訓練が深まるにつれて、自己の進歩で少しずつシステムのパフォーマンス。ゲームの結果が良くなっていると、同時に、ニューラルネットワークは、より正確です。
AlphaGo ゼロによる知識獲得の過程
"これらの技術的な詳細は、以前のバージョンよりも強い理由は、我々はもはや人間の知識の限界を持って、それは最高の選手がフィールドに行く AlphaGo することを学ぶことができます。AlphaGo チームリーダーのデビッドシルバ (デイブの断片) と述べた。
デビッド·シルバの導入によると、AlphaGo ゼロは、新しい強化学習法を使用して、自分は教師になることができます。も、1つのニューラルネットワークは、神経回路網の検索アルゴリズムは、強力な、自己のチェスを再生するだけから、システムに行くのか分からない。
自己ゲームの増加に伴い、ニューラルネットワークは徐々に調整され、次のステップの予測能力を強化し、最終的にゲームに勝つ。さらに強力で、綿密なトレーニングで、DeepMind チームは、AlphaGo ゼロも独立してゲームのルールを発見し、新しい戦略のうち、この古代のチェスラウンドゲームに新しい洞察力をもたらすことがわかった。
3日間の自習、AlphaGo の古いバージョンを破った
"これらの技術的な詳細は、以前のバージョンよりも強い理由は、我々はもはや人間の知識の限界を持って、それは最高の選手がフィールドに行く AlphaGo することを学ぶことができます。AlphaGo チームリーダーのデビッドシルバ (デイブの断片) と述べた。
デビッド·シルバの導入によると、AlphaGo ゼロは、新しい強化学習法を使用して、自分は教師になることができます。も、1つのニューラルネットワークは、神経回路網の検索アルゴリズムは、強力な、自己のチェスを再生するだけから、システムに行くのか分からない。
自己ゲームの増加に伴い、ニューラルネットワークは徐々に調整され、次のステップの予測能力を強化し、最終的にゲームに勝つ。さらに強力で、綿密なトレーニングで、DeepMind チームは、AlphaGo ゼロも独立してゲームのルールを発見し、新しい戦略のうち、この古代のチェスラウンドゲームに新しい洞察力をもたらすことがわかった。
3日間の自習、AlphaGo の古いバージョンを破った
上記の違いに加えて、以前のバージョンと比較して3面で AlphaGo ゼロは明らかな違いを持っている
AlphaGo-ゼロのトレーニング時間軸
前者は人工的に設計された機能入力の数が少ないが、最初に、AlphaGo ゼロは、入力としてチェスに黒と白を使用します。
次に、AlphaGo ゼロは1つのニューラルネットワークのみを使用します。以前のバージョンでは、AlphaGo は、次の移動を選択する "ネットワーク" の戦略を使用して、勝者の後に各ステップを予測するために "バリューネットワーク" の使用。しかし、新しいバージョンでは、2つのニューラルネットワークを1つにすることができます。それは、より効率的なトレーニングと評価を得ることができます。
第三に、AlphaGo ゼロは、高速、ランダムウォーク法を使用していません。以前のバージョンでは、AlphaGo は、ゲームプレーヤーは、現在の状況からゲームに勝つかを予測するための高速ウォーク方法です。逆に、新しいバージョンは、ゲームの状況を評価するために、ニューラルネットワークの高品質に依存することです。
ランキングのいくつかのバージョンを AlphaGo
カザフスタンビスケーとシルバの導入によると、AlphaGo のこれらの異なるヘルプバージョンは、システムで改善されており、アルゴリズムの変更は、システムが強く、より効果的になるようになります。
自己トレーニングのわずか3日後、強力な AlphaGo の旧バージョンで李獅子以上の前の勝利を打つ AlphaGo ゼロ、彼らは100:0 です。セルフトレーニングの40日後、AlphaGo ゼロビート AlphaGo マスターバージョン。世界で初めてランクインしたキジャも含め、世界トップの選手を「名人」が破った。
人工知能 DeepMind ミッションを使用して人間社会の進歩を促進するために、究極の AlphaGo は行かなかった、彼らの目標は、一般的なを作成する AlphaGo を使用して、の宇宙の究極のツールを探るされています。AlphaGo ゼロの昇天、DeepMind は、人工知能技術のブレークスルーを使用して、人類の運命の変化を見てみましょう。彼らは現在、英国の医療機関や電力エネルギーセクターの協力、治療効率とエネルギー効率を向上させるアクティブです。