























阿尔法犬进化: 自我研究3天100:0 轧制李石狮版的老狗
chinatopwin
chinatopwin
2017-10-19 09:55:03
伦敦当地时间在 18:00 10月18日 (北京时间 19 01:00), AlphaGo 再次在世界顶尖科学杂志的性质。"
一年多前, AlphaGo 是2016年1月28日期间的封面文章, Deepmind 发表了一篇重文, 介绍了这款击败欧洲象棋迷慧的人工智能方案。
今年 5月, 比分为3:0 的中国选手 kija, AlphaGo 宣布退役, 但 DeepMind 没有停止研究的步伐。伦敦当地时间 10月18日, DeepMind 队宣布了最强的版本 AlphaGo, 代号 AlphaGo 零。其独特的秘籍, 是 "自我自学成才"。而且, 从白纸开始, 零基础学习, 在短短3天内, 成为顶尖高手。
该小组说, 在 AlphaGo 0 之前, 已经超过了 AlphaGo 的所有版本的级别。已经赢得了反对韩国球员李石狮的 AlphaGo, AlphaGo 100:0 已经取得了压倒性的成功。DeepMind 小组将研究 AlphaGo 零的形式, 发表在10月18日的《自然》杂志上。
"在两年内 AlphaGo 取得了惊人的成就。现在, AlphaGo 零是我们最强的版本, 它提出了很多。零点来提高计算效率, 而不使用任何数据的人棋, "AlphaGo 的父亲, DeepMind 创始人兼首席执行官 Demes Sabis (Demis 哈萨比斯) 说," 最后, 我们要用它的算法突破, 帮助解决现实世界亟待解决的问题, 如蛋白质折叠或设计新材料。如果我们 AlphaGo, 就能在这些问题上取得进展, 它有可能促进对生活的理解, 并以积极的方式影响我们的生活。
不再受人类知识的限制, 只有 4 TPU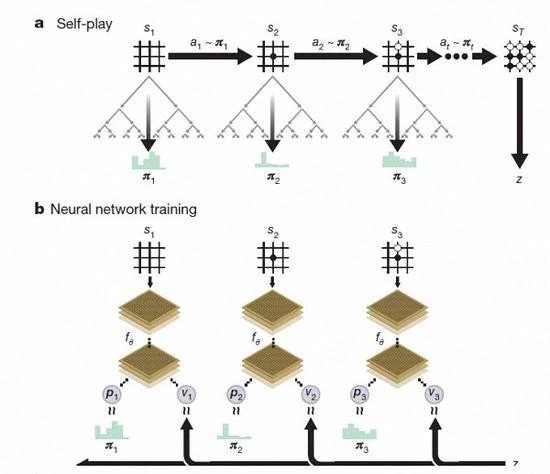
AlphaGo 以前的版本, 以百万计的人类专家围棋, 加强对自学培训的监督。
在击败职业球员的 go, 它经历了几个月的训练, 依靠多台机器和 48 TPU (谷歌芯片设计, 以加快深神经网络计算)
AlphaGo 零是在这个基础上的质量改进。最大的区别在于它不再需要人类的数据。也就是说, 它与人类象棋没有联系。研究 & 开发团队只是让它自由地下棋的棋盘上, 然后自我游戏。值得一提的是, AlphaGo 零是一个 "低碳", 用一台机器和 4 TPU, 大大节省资源。
AlphaGo 零强化学习下的自下棋
经过几天的训练, AlphaGo 零完成了近500万盘的自我游戏, 可以超越人类, 打败所有以前版本的 AlphaGo. DeepMind 团队在官方博客上说, 用更新的神经网络和搜索算法重组零, 随着训练的深化, 系统的性能略有进步。游戏结果越来越好, 同时神经网络更准确。
除上述差异外, AlphaGo 零在3方面与前一版本相比有明显差异
AlphaGo 训练时间轴
首先, AlphaGo 零只使用黑白棋盘作为输入, 而前者包括少量人工设计的特征输入
其次, AlphaGo 零只使用一个单一的神经网络。在以前的版本中, AlphaGo 采用 "网络" 策略选择下一步, 并利用 "价值网络" 来预测每一个步骤后的赢家。但在新的版本中, 两个神经网络可以做一个。它可以使培训和评估更有效率。
第三, AlphaGo 零不使用快速、随机行走的方法。在以前的版本中, AlphaGo 是快速行走的方法, 以预测哪个游戏玩家会从当前的情况中赢得比赛。相反, 新的版本是依靠高品质的神经网络来评估游戏的情况。
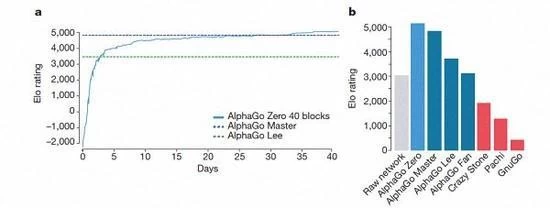
AlphaGo 几个版本的排名
根据哈萨克斯坦比斯开湾和席尔瓦的介绍, 这些不同的帮助版本的 AlphaGo 在系统中得到了改进, 算法的变化使系统变得更加强大和有效。
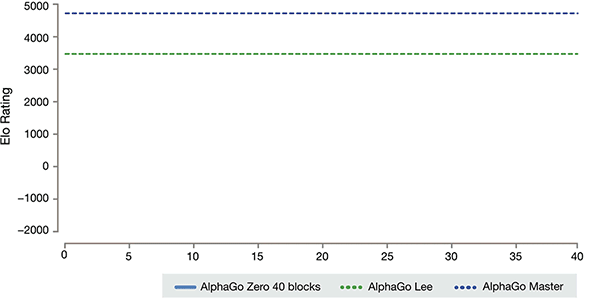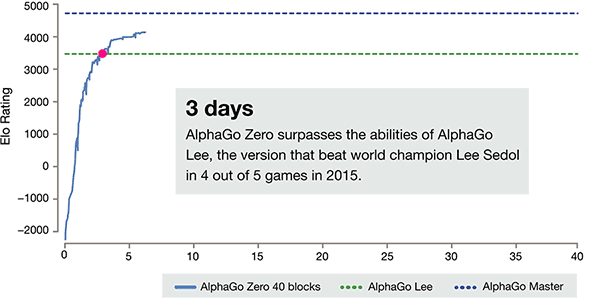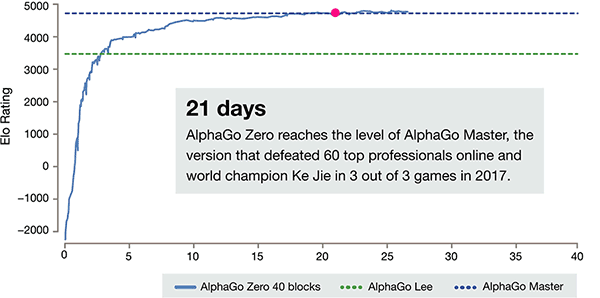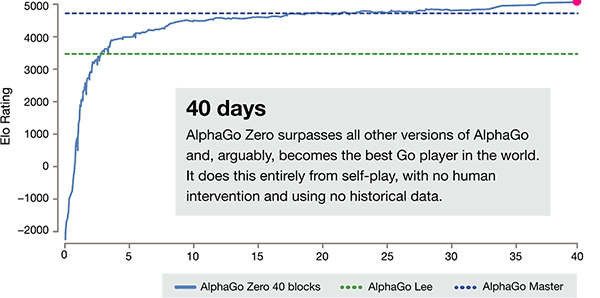
经过短短3天的自我训练, AlphaGo 零强击败了以前的胜利, 在 AlphaGo 的旧版本里, 他们是100:0。经过40天的自我训练, AlphaGo 零节拍 AlphaGo 大师版。"大师" 击败了世界顶尖球员, 甚至包括 kija 名列世界首位。
为了促进人类社会的进步, 利用人工智能 DeepMind 的使命, 终极 AlphaGo 没有走, 他们的目标一直是用 AlphaGo 来创造一个将军, 探索宇宙的终极工具。AlphaGo 零的提升, 让 DeepMind 看到人类命运的改变, 利用人工智能技术的突破。他们目前正积极与英国医疗机构和电力能源部门合作, 提高治疗效率和能效。
一年多前, AlphaGo 是2016年1月28日期间的封面文章, Deepmind 发表了一篇重文, 介绍了这款击败欧洲象棋迷慧的人工智能方案。
今年 5月, 比分为3:0 的中国选手 kija, AlphaGo 宣布退役, 但 DeepMind 没有停止研究的步伐。伦敦当地时间 10月18日, DeepMind 队宣布了最强的版本 AlphaGo, 代号 AlphaGo 零。其独特的秘籍, 是 "自我自学成才"。而且, 从白纸开始, 零基础学习, 在短短3天内, 成为顶尖高手。
该小组说, 在 AlphaGo 0 之前, 已经超过了 AlphaGo 的所有版本的级别。已经赢得了反对韩国球员李石狮的 AlphaGo, AlphaGo 100:0 已经取得了压倒性的成功。DeepMind 小组将研究 AlphaGo 零的形式, 发表在10月18日的《自然》杂志上。
"在两年内 AlphaGo 取得了惊人的成就。现在, AlphaGo 零是我们最强的版本, 它提出了很多。零点来提高计算效率, 而不使用任何数据的人棋, "AlphaGo 的父亲, DeepMind 创始人兼首席执行官 Demes Sabis (Demis 哈萨比斯) 说," 最后, 我们要用它的算法突破, 帮助解决现实世界亟待解决的问题, 如蛋白质折叠或设计新材料。如果我们 AlphaGo, 就能在这些问题上取得进展, 它有可能促进对生活的理解, 并以积极的方式影响我们的生活。
不再受人类知识的限制, 只有 4 TPU
AlphaGo 以前的版本, 以百万计的人类专家围棋, 加强对自学培训的监督。
在击败职业球员的 go, 它经历了几个月的训练, 依靠多台机器和 48 TPU (谷歌芯片设计, 以加快深神经网络计算)
AlphaGo 零是在这个基础上的质量改进。最大的区别在于它不再需要人类的数据。也就是说, 它与人类象棋没有联系。研究 & 开发团队只是让它自由地下棋的棋盘上, 然后自我游戏。值得一提的是, AlphaGo 零是一个 "低碳", 用一台机器和 4 TPU, 大大节省资源。
AlphaGo 零强化学习下的自下棋
经过几天的训练, AlphaGo 零完成了近500万盘的自我游戏, 可以超越人类, 打败所有以前版本的 AlphaGo. DeepMind 团队在官方博客上说, 用更新的神经网络和搜索算法重组零, 随着训练的深化, 系统的性能略有进步。游戏结果越来越好, 同时神经网络更准确。
AlphaGo 零获取知识的过程
"这些技术细节比以前的版本更强的原因, 我们不再有人类知识的极限, 它可以学会 AlphaGo 它的最高的球员去领域。AlphaGo 队长大卫. 席尔瓦说。
根据大卫·席尔瓦的介绍, AlphaGo 零使用新的强化学习方法, 让自己成为老师。甚至不知道什么是系统去, 只是从一个单一的神经网络, 神经网络搜索算法是强大的, 自下棋。
随着自我游戏的增加, 神经网络逐渐调整, 增强了预测能力的下一步, 最终赢得了比赛。更强大的, 与 in-depth 的训练, DeepMind 团队发现, AlphaGo 零也独立发现游戏规则, 并出了新的战略, 带来新的洞察力, 这古老的国际象棋回合游戏。
自我学习3天, 击败旧版本的 AlphaGo
"这些技术细节比以前的版本更强的原因, 我们不再有人类知识的极限, 它可以学会 AlphaGo 它的最高的球员去领域。AlphaGo 队长大卫. 席尔瓦说。
根据大卫·席尔瓦的介绍, AlphaGo 零使用新的强化学习方法, 让自己成为老师。甚至不知道什么是系统去, 只是从一个单一的神经网络, 神经网络搜索算法是强大的, 自下棋。
随着自我游戏的增加, 神经网络逐渐调整, 增强了预测能力的下一步, 最终赢得了比赛。更强大的, 与 in-depth 的训练, DeepMind 团队发现, AlphaGo 零也独立发现游戏规则, 并出了新的战略, 带来新的洞察力, 这古老的国际象棋回合游戏。
自我学习3天, 击败旧版本的 AlphaGo
除上述差异外, AlphaGo 零在3方面与前一版本相比有明显差异
AlphaGo 训练时间轴
首先, AlphaGo 零只使用黑白棋盘作为输入, 而前者包括少量人工设计的特征输入
其次, AlphaGo 零只使用一个单一的神经网络。在以前的版本中, AlphaGo 采用 "网络" 策略选择下一步, 并利用 "价值网络" 来预测每一个步骤后的赢家。但在新的版本中, 两个神经网络可以做一个。它可以使培训和评估更有效率。
第三, AlphaGo 零不使用快速、随机行走的方法。在以前的版本中, AlphaGo 是快速行走的方法, 以预测哪个游戏玩家会从当前的情况中赢得比赛。相反, 新的版本是依靠高品质的神经网络来评估游戏的情况。
AlphaGo 几个版本的排名
根据哈萨克斯坦比斯开湾和席尔瓦的介绍, 这些不同的帮助版本的 AlphaGo 在系统中得到了改进, 算法的变化使系统变得更加强大和有效。
经过短短3天的自我训练, AlphaGo 零强击败了以前的胜利, 在 AlphaGo 的旧版本里, 他们是100:0。经过40天的自我训练, AlphaGo 零节拍 AlphaGo 大师版。"大师" 击败了世界顶尖球员, 甚至包括 kija 名列世界首位。
为了促进人类社会的进步, 利用人工智能 DeepMind 的使命, 终极 AlphaGo 没有走, 他们的目标一直是用 AlphaGo 来创造一个将军, 探索宇宙的终极工具。AlphaGo 零的提升, 让 DeepMind 看到人类命运的改变, 利用人工智能技术的突破。他们目前正积极与英国医疗机构和电力能源部门合作, 提高治疗效率和能效。