























Alfa Dog Evolution: Self Study 3 Days 100:0 Rolling Li shishi Version des alten Hundes
chinatopwin
chinatopwin
2017-10-19 09:55:03
London Local Time auf 18:00 am 18. Oktober (Peking-Zeit 19 01:00), AlphaGo wieder auf der weltweit führenden wissenschaftlichen Zeitschrift Nature. "
Vor mehr als einem Jahr, AlphaGo ist ein Cover-Artikel in der Periode Januar 28, 2016, Deepmind ausgestellt ein schweres Papier, eingeführt dieses Beat der EM-Schach-Fan Hui Artificial Intelligence Program.
Im Mai dieses Jahres, der Score von 3:0, um den chinesischen Spieler Kija zu gewinnen, kündigte AlphaGo seinen Ruhestand an, aber DeepMind hat nicht das Tempo der Forschung gestoppt. London Local Time am 18. Oktober kündigte das DeepMind-Team die stärkste Version von AlphaGo an, Codename AlphaGo Zero. seine einzigartigen Cheats, ist "Self Autodidakt". Darüber hinaus, von Anfang an ein Weißbuch, Zero based Learning, in nur 3 Tagen, wird der oberste Meister.
Das Team sagte, bevor AlphaGo Zero die Höhe aller Versionen von AlphaGo überschritten hat. haben gegen südkoreanische Spieler Li shishi's Version von AlphaGo gewonnen, AlphaGo Zero 100:0 hat überwältigende Erfolge erzielt. Das DeepMind-Team wird auf AlphaGo Zero in Form eines Papiers forschen, das im 18. Oktober "Nature Journal" veröffentlicht wurde.
"innerhalb von zwei Jahren AlphaGo erreicht amazing." Nun, AlphaGo Zero ist unsere stärkste Version, wirft es eine Menge. Zero zur Verbesserung der Effizienz der Computational und keine Daten von menschlichem Schach zu verwenden, "der Vater des AlphaGo, DeepMind Mitbegründer und CEO demes ha SABIS (Demis Hassabis) sagte:" am Ende wollen wir es den Algorithmus des Durchbruch zu benutzen, um zu helfen, reale Welt zu lösen Probleme dringend, wie Protein Falten oder Design neue Materialien. Wenn wir AlphaGo, können Fortschritte in diesen Fragen machen, es hat das Potenzial, das Verständnis des Lebens zu fördern, und auf eine positive Art und Weise, unser Leben zu beeinflussen
Nicht mehr durch menschliches Wissen begrenzt, nur 4 TPU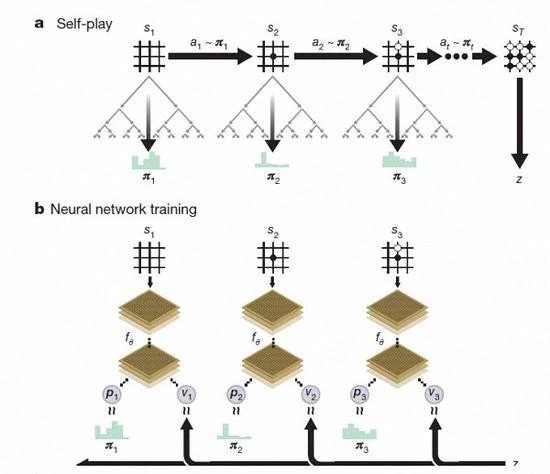
AlphaGo die frühere Version, mit Millionen von Human-Experten gehen Schach, und verstärken die Aufsicht über das Lernen von Self-Training.
Vor der Niederlage der professionellen Spieler der Go, ging es durch die Monate der Ausbildung, die sich auf mehrere Maschinen und 48 TPU (Google-Chips entwickelt, um die Beschleunigung Deep Neural Network Computing)
AlphaGo Zero ist eine qualitative Verbesserung auf dieser Basis. Der größte Unterschied besteht darin, dass die menschliche Daten nicht mehr benötigt werden. Das heißt, es hat keinen Kontakt mit menschlichem Schach. R & D Team lassen Sie es einfach frei, Schach auf dem Brett zu spielen, und dann selbst Spiel. Es lohnt sich zu erwähnen, dass AlphaGo Zero ein "Low Carbon" ist, um eine Maschine und 4 TPU zu benutzen, spart Ressourcen.
AlphaGo Zero Verstärkung Lernen unter dem Self Play Chess
Nach ein paar Tagen der Ausbildung, AlphaGo Zero abgeschlossen fast 5 Millionen Disc Self Spiel, kann über die menschliche, und besiegte alle bisherigen Versionen der AlphaGo. DeepMind Team sagte auf dem offiziellen Blog, mit dem aktualisierten neuralen Netzwerk und Suche Algorithmen von rekombinationant Zero, wie die Ausbildung vertieft, die Leistung des Systems ein wenig in Self Progress. Das Spiel Ergebnisse werden immer besser und besser, zur gleichen Zeit, neuronale Netz ist genauer.
Zusätzlich zu den obigen unterschieden hat AlphaGo Zero in 3 Aspekten verglichen mit der vorhergehenden Version offensichtliche Differenz
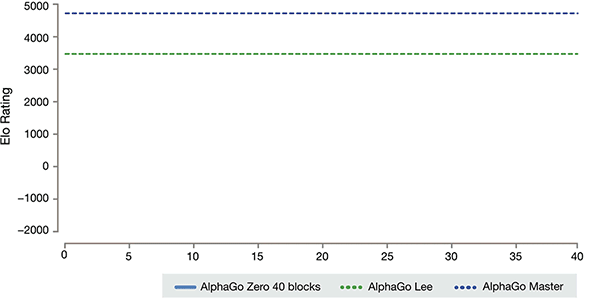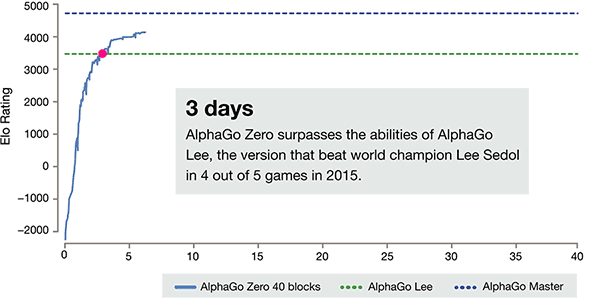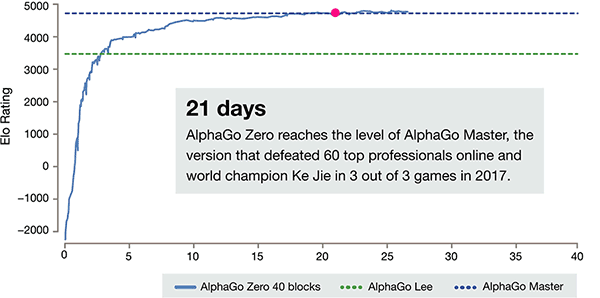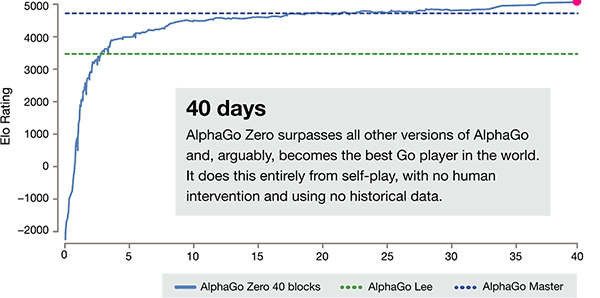
Die Training-Zeitachse von AlphaGo-Zero
Erstens, AlphaGo NULL verwendet nur schwarz und weiß auf dem Schachbrett als Input, während erstere eine kleine Anzahl von künstlich entworfenen KE-Eingaben einschließt
Zweitens nutzt AlphaGo Zero nur ein einziges neurales Netzwerk. In früheren Versionen verwendet die AlphaGo die Strategie des "Netzwerks", um den nächsten Schritt zu wählen, und die Verwendung von "Value Network", um den einzelnen Schritten nach dem Sieger vorherzusagen. Aber in der neuen Version kann das beiden neuralen Netz gebildet werden. Es kann die Ausbildung und Evaluierung effizienter zu erhalten.
Drittens, AlphaGo Zero nutzt nicht die schnelle, zufällige Walk-Methode. In früheren Versionen ist AlphaGo fast Walk Methode, um vorherzusagen, welcher Spieler das Spiel aus der aktuellen Situation gewinnen wird. Im Gegenteil, die neue Version ist es, auf die hohe Qualität des neuronalen Netzes zu bewerten Spiel Situation zu verlassen.
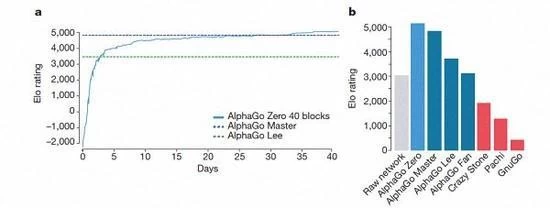
AlphaGo mehrere Versionen der Rangliste
Nach Kasachstan Vizcaya und Silva Einführung, diese verschiedenen Hilfe-Version von AlphaGo hat sich im System verbessert, und die Änderung des Algorithmus machen das System zu stärker und effektiver.
Nach nur 3 Tagen der Self-Training, AlphaGo Zero auf den starken Beats den vorangegangenen Sieg über Li shishi in der alten Version von AlphaGo, Sie sind 100:0. Nach 40 Tagen der Self-Schulung, AlphaGo Zero Beat AlphaGo Master-Version. "Master" Beat the World's Top-Spieler, auch mit Kija Rang ersten in der Welt.
Um den Fortschritt der menschlichen Gesellschaft mit künstlicher Intelligenz DeepMind Mission zu fördern, hat die ultimative AlphaGo nicht gehen, Ihr Ziel war es, AlphaGo zu verwenden, um einen allgemeinen zu schaffen, erforschen Sie die entscheidenden Hilfsmittel des Universums von. AlphaGo Zero's Ascension, lassen Sie DeepMind sehen, eine Veränderung im Schicksal der Menschheit mit dem künstlichen Intelligenz Technologie Durchbruch. Sie sind derzeit aktiv und die britische medizinische Institutionen und Energie-Sektor Zusammenarbeit, Verbesserung der Behandlung Effizienz und Energieeffizienz.
Vor mehr als einem Jahr, AlphaGo ist ein Cover-Artikel in der Periode Januar 28, 2016, Deepmind ausgestellt ein schweres Papier, eingeführt dieses Beat der EM-Schach-Fan Hui Artificial Intelligence Program.
Im Mai dieses Jahres, der Score von 3:0, um den chinesischen Spieler Kija zu gewinnen, kündigte AlphaGo seinen Ruhestand an, aber DeepMind hat nicht das Tempo der Forschung gestoppt. London Local Time am 18. Oktober kündigte das DeepMind-Team die stärkste Version von AlphaGo an, Codename AlphaGo Zero. seine einzigartigen Cheats, ist "Self Autodidakt". Darüber hinaus, von Anfang an ein Weißbuch, Zero based Learning, in nur 3 Tagen, wird der oberste Meister.
Das Team sagte, bevor AlphaGo Zero die Höhe aller Versionen von AlphaGo überschritten hat. haben gegen südkoreanische Spieler Li shishi's Version von AlphaGo gewonnen, AlphaGo Zero 100:0 hat überwältigende Erfolge erzielt. Das DeepMind-Team wird auf AlphaGo Zero in Form eines Papiers forschen, das im 18. Oktober "Nature Journal" veröffentlicht wurde.
"innerhalb von zwei Jahren AlphaGo erreicht amazing." Nun, AlphaGo Zero ist unsere stärkste Version, wirft es eine Menge. Zero zur Verbesserung der Effizienz der Computational und keine Daten von menschlichem Schach zu verwenden, "der Vater des AlphaGo, DeepMind Mitbegründer und CEO demes ha SABIS (Demis Hassabis) sagte:" am Ende wollen wir es den Algorithmus des Durchbruch zu benutzen, um zu helfen, reale Welt zu lösen Probleme dringend, wie Protein Falten oder Design neue Materialien. Wenn wir AlphaGo, können Fortschritte in diesen Fragen machen, es hat das Potenzial, das Verständnis des Lebens zu fördern, und auf eine positive Art und Weise, unser Leben zu beeinflussen
Nicht mehr durch menschliches Wissen begrenzt, nur 4 TPU
AlphaGo die frühere Version, mit Millionen von Human-Experten gehen Schach, und verstärken die Aufsicht über das Lernen von Self-Training.
Vor der Niederlage der professionellen Spieler der Go, ging es durch die Monate der Ausbildung, die sich auf mehrere Maschinen und 48 TPU (Google-Chips entwickelt, um die Beschleunigung Deep Neural Network Computing)
AlphaGo Zero ist eine qualitative Verbesserung auf dieser Basis. Der größte Unterschied besteht darin, dass die menschliche Daten nicht mehr benötigt werden. Das heißt, es hat keinen Kontakt mit menschlichem Schach. R & D Team lassen Sie es einfach frei, Schach auf dem Brett zu spielen, und dann selbst Spiel. Es lohnt sich zu erwähnen, dass AlphaGo Zero ein "Low Carbon" ist, um eine Maschine und 4 TPU zu benutzen, spart Ressourcen.
AlphaGo Zero Verstärkung Lernen unter dem Self Play Chess
Nach ein paar Tagen der Ausbildung, AlphaGo Zero abgeschlossen fast 5 Millionen Disc Self Spiel, kann über die menschliche, und besiegte alle bisherigen Versionen der AlphaGo. DeepMind Team sagte auf dem offiziellen Blog, mit dem aktualisierten neuralen Netzwerk und Suche Algorithmen von rekombinationant Zero, wie die Ausbildung vertieft, die Leistung des Systems ein wenig in Self Progress. Das Spiel Ergebnisse werden immer besser und besser, zur gleichen Zeit, neuronale Netz ist genauer.
Der Prozess des Erwerbs von Kenntnissen durch AlphaGo Zero
"der Grund, warum diese technischen Details stärker sind als die frühere Version, haben wir nicht mehr die Grenzen des menschlichen Wissens, kann es lernen, AlphaGo seiner höchsten Spieler gehen Feld." AlphaGo Teamleiter David Silva (Dave Remasuri) sagte.
Nach David Silva Einführung, AlphaGo Zero nutzt die neue Verstärkung Learning-Methode, lassen Sie sich selbst zum Lehrer. Nicht einmal wissen, was ein System zu gehen, nur von einem einzigen neuronalen Netz, der Neural Network Search Algorithmus ist mächtig, das selbst spielen Schach.
Mit der Zunahme des Self-Spiels, wird das neuronale Netz allmählich angepasst, die Vorhersage der Fähigkeit des nächsten Schrittes erhöhen und letztendlich das Spiel gewinnen. Leistungsfähiger, mit eingehender Ausbildung, fanden die DeepMind Mannschaft, dass AlphaGo Zero auch selbständig die Spielregeln und aus der neuen Strategie entdeckte, neue Einblicke in dieses antike Spiel der Schach-Runde bringen.
Self Study für 3 Tage, Beat die alte Version von AlphaGo
"der Grund, warum diese technischen Details stärker sind als die frühere Version, haben wir nicht mehr die Grenzen des menschlichen Wissens, kann es lernen, AlphaGo seiner höchsten Spieler gehen Feld." AlphaGo Teamleiter David Silva (Dave Remasuri) sagte.
Nach David Silva Einführung, AlphaGo Zero nutzt die neue Verstärkung Learning-Methode, lassen Sie sich selbst zum Lehrer. Nicht einmal wissen, was ein System zu gehen, nur von einem einzigen neuronalen Netz, der Neural Network Search Algorithmus ist mächtig, das selbst spielen Schach.
Mit der Zunahme des Self-Spiels, wird das neuronale Netz allmählich angepasst, die Vorhersage der Fähigkeit des nächsten Schrittes erhöhen und letztendlich das Spiel gewinnen. Leistungsfähiger, mit eingehender Ausbildung, fanden die DeepMind Mannschaft, dass AlphaGo Zero auch selbständig die Spielregeln und aus der neuen Strategie entdeckte, neue Einblicke in dieses antike Spiel der Schach-Runde bringen.
Self Study für 3 Tage, Beat die alte Version von AlphaGo
Zusätzlich zu den obigen unterschieden hat AlphaGo Zero in 3 Aspekten verglichen mit der vorhergehenden Version offensichtliche Differenz
Die Training-Zeitachse von AlphaGo-Zero
Erstens, AlphaGo NULL verwendet nur schwarz und weiß auf dem Schachbrett als Input, während erstere eine kleine Anzahl von künstlich entworfenen KE-Eingaben einschließt
Zweitens nutzt AlphaGo Zero nur ein einziges neurales Netzwerk. In früheren Versionen verwendet die AlphaGo die Strategie des "Netzwerks", um den nächsten Schritt zu wählen, und die Verwendung von "Value Network", um den einzelnen Schritten nach dem Sieger vorherzusagen. Aber in der neuen Version kann das beiden neuralen Netz gebildet werden. Es kann die Ausbildung und Evaluierung effizienter zu erhalten.
Drittens, AlphaGo Zero nutzt nicht die schnelle, zufällige Walk-Methode. In früheren Versionen ist AlphaGo fast Walk Methode, um vorherzusagen, welcher Spieler das Spiel aus der aktuellen Situation gewinnen wird. Im Gegenteil, die neue Version ist es, auf die hohe Qualität des neuronalen Netzes zu bewerten Spiel Situation zu verlassen.
AlphaGo mehrere Versionen der Rangliste
Nach Kasachstan Vizcaya und Silva Einführung, diese verschiedenen Hilfe-Version von AlphaGo hat sich im System verbessert, und die Änderung des Algorithmus machen das System zu stärker und effektiver.
Nach nur 3 Tagen der Self-Training, AlphaGo Zero auf den starken Beats den vorangegangenen Sieg über Li shishi in der alten Version von AlphaGo, Sie sind 100:0. Nach 40 Tagen der Self-Schulung, AlphaGo Zero Beat AlphaGo Master-Version. "Master" Beat the World's Top-Spieler, auch mit Kija Rang ersten in der Welt.
Um den Fortschritt der menschlichen Gesellschaft mit künstlicher Intelligenz DeepMind Mission zu fördern, hat die ultimative AlphaGo nicht gehen, Ihr Ziel war es, AlphaGo zu verwenden, um einen allgemeinen zu schaffen, erforschen Sie die entscheidenden Hilfsmittel des Universums von. AlphaGo Zero's Ascension, lassen Sie DeepMind sehen, eine Veränderung im Schicksal der Menschheit mit dem künstlichen Intelligenz Technologie Durchbruch. Sie sind derzeit aktiv und die britische medizinische Institutionen und Energie-Sektor Zusammenarbeit, Verbesserung der Behandlung Effizienz und Energieeffizienz.