























Alfa Dog Evolution: auto Study 3 jours 100:0 Rolling Li version de l'ancien chien
chinatopwin
chinatopwin
2017-10-19 09:55:03
Heure locale de Londres à 18:00 le 18 octobre (Beijing Time 19 01:00), AlphaGo à nouveau sur la revue scientifique la plus populaire du monde. "
Il ya plus d'un an, AlphaGo est un article de couverture dans la période janvier 28, 2016, Deepmind publié un papier lourd, a présenté ce Beat le Championnat d'Europe d'échecs fan hui de l'intelligence artificielle programme.
En mai de cette année, le score de 3:0 pour gagner le joueur chinois kija, AlphaGo a annoncé sa retraite, mais DeepMind n'a pas empêché le rythme de la recherche. Heure locale de Londres le 18 octobre, l'équipe de DeepMind a annoncé la version la plus forte de AlphaGo, nom de code AlphaGo Zero. ses tricheurs uniques, est "Self-autodidacte". En outre, dès le début d'un livre blanc, l'apprentissage à base zéro, en seulement 3 jours, devenant le maître supérieur.
L'équipe a dit, avant AlphaGo Zero a dépassé le niveau de toutes les versions de AlphaGo. ont gagné contre les joueurs sud-coréens Li, la version de AlphaGo, AlphaGo Zero 100:0 a atteint un succès écrasant. DeepMind équipe fera des recherches sur AlphaGo Zero sous la forme d'un papier, publié dans le 18 octobre "nature journal."
"dans les deux ans AlphaGo atteint étonnant." Maintenant, AlphaGo Zero est notre version la plus forte, il soulève beaucoup de. Zéro pour améliorer l'efficacité de calcul, et de ne pas utiliser de données d'échecs humains, "le père de la AlphaGo, DeepMind co-fondateur et PDG dèmes ha Sabis (Demis Hassabis) a dit," à la fin, nous voulons l'utiliser l'algorithme de percée, pour aider à résoudre le monde réel problèmes urgents, tels que le pliage de protéines ou de nouveaux matériaux de conception. «Si nous AlphaGo, pouvons faire des progrès sur ces questions, il a le potentiel de promouvoir la compréhension de la vie, et d'une manière positive d'affecter nos vies»
Ne sont plus limités par la connaissance humaine, seulement 4 TPU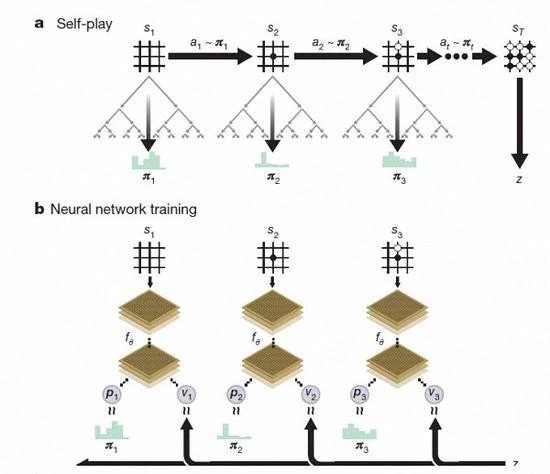
AlphaGo la version précédente, avec des millions d'experts humains vont échecs, et de renforcer la supervision de l'apprentissage de l'autoformation.
Avant de vaincre le joueur professionnel de la Go, il est passé par des mois de formation, en s'appuyant sur plusieurs machines et 48 TPU (Google chips conçu pour accélérer le réseau neuronal Deep Computing)
AlphaGo Zero est une amélioration qualitative sur cette base. La plus grande différence est qu'il n'est plus nécessaire de données humaines. C'est à dire, il n'a pas de contact avec les échecs humains. Équipe de R & D il suffit de laisser libre de jouer aux échecs sur le plateau, puis Self Game. Il convient de mentionner que AlphaGo Zero est un "Low Carbon", d'utiliser une machine et 4 TPU, sauve considérablement les ressources.
AlphaGo Zero renforcement d'apprentissage sous le jeu d'échecs auto
Après quelques jours de formation, AlphaGo Zero terminé près de 5 millions Disc Self Game, peut aller au-delà de l'homme, et défait toutes les versions précédentes de l'AlphaGo DeepMind équipe a déclaré sur le blog officiel, avec le réseau neuronal mis à jour et des algorithmes de recherche de zéro recombinant, comme l'approfondissement de la formation, la performance du système un peu dans le progrès de soi. Les résultats du jeu sont de mieux en mieux, en même temps, le réseau neuronal est plus précis.
En plus des différences ci-dessus, AlphaGo zéro en 3 aspects par rapport à la version précédente a une différence évidente
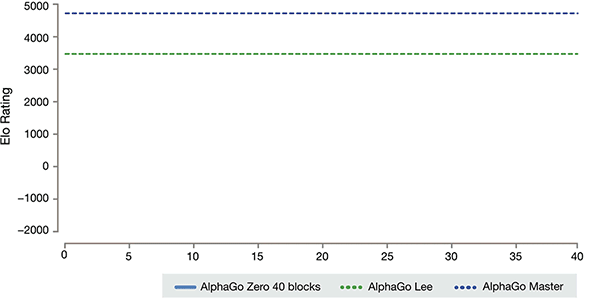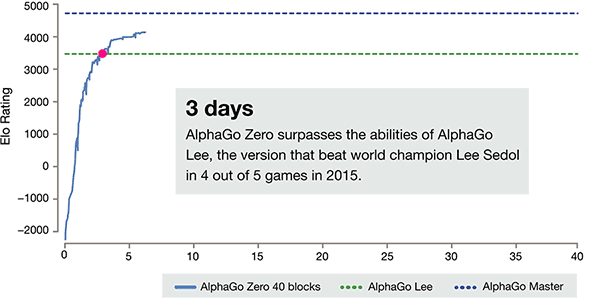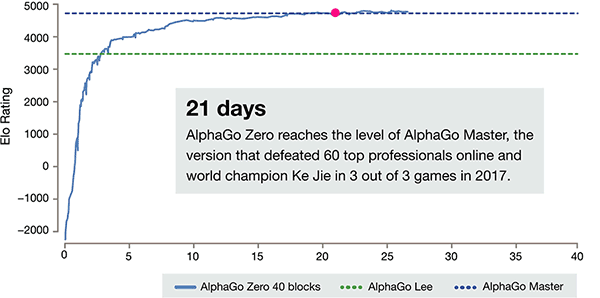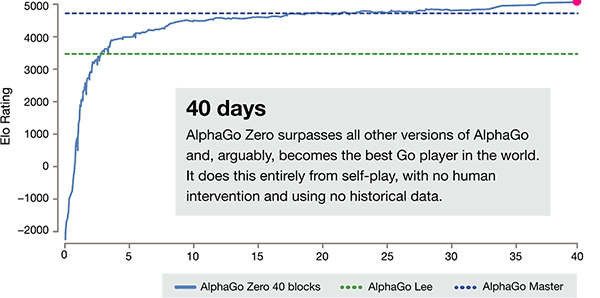
L'axe de temps de formation de AlphaGo-Zero
D'abord, AlphaGo Zero utilise uniquement le noir et blanc sur l'échiquier comme entrée, tandis que le premier comprend un petit nombre d'entrées de fonctionnalités artificiellement conçues
Deuxièmement, AlphaGo Zero n'utilise qu'un seul réseau neuronal. Dans les versions précédentes, le AlphaGo utilise la stratégie de «réseau» pour choisir le prochain mouvement, et l'utilisation du «réseau de valeur» pour prévoir chaque étape après le vainqueur. Mais dans la nouvelle version, le réseau neuronal deux peut être fait un. Il peut obtenir la formation et l'évaluation plus efficace.
Troisièmement, AlphaGo Zero n'utilise pas la méthode de marche rapide et aléatoire. Dans les versions précédentes, AlphaGo est rapide méthode de marche pour prédire quel joueur de jeu va gagner le jeu de la situation actuelle. Au contraire, la nouvelle version est de s'appuyer sur la haute qualité du réseau neuronal pour évaluer la situation du jeu.
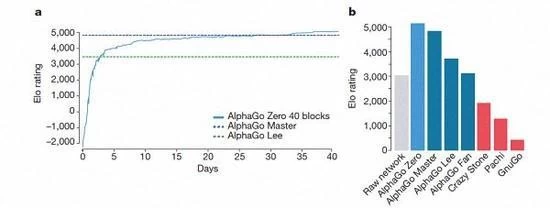
AlphaGo plusieurs versions du classement
Selon le Kazakhstan Biscaye et Silva introduction, ces différentes versions d'aide de AlphaGo s'est améliorée dans le système, et le changement de l'algorithme de rendre le système de devenir plus fort et plus efficace.
Après seulement 3 jours de self training, AlphaGo Zero sur la forte bat la victoire précédente sur Li-chicha dans l'ancienne version de AlphaGo, ils sont 100:0. Après 40 jours de self training, AlphaGo Zero Beat AlphaGo Master version. "Master" battre les meilleurs joueurs du monde, même y compris kija classé premier dans le monde.
Pour promouvoir le progrès de la société humaine en utilisant l'intelligence artificielle DeepMind mission, l'ultime AlphaGo n'est pas allé, leur but a été d'utiliser AlphaGo pour créer un général, d'explorer les outils ultimes de l'univers de. L'ascension de AlphaGo Zero, laissez DeepMind voir un changement dans le destin de l'humanité en utilisant la percée de technologie de l'intelligence artificielle. Ils sont actuellement actifs et les institutions médicales britanniques et la coopération du secteur de l'énergie électrique, améliorent l'efficacité du traitement et l'efficacité énergétique.
Il ya plus d'un an, AlphaGo est un article de couverture dans la période janvier 28, 2016, Deepmind publié un papier lourd, a présenté ce Beat le Championnat d'Europe d'échecs fan hui de l'intelligence artificielle programme.
En mai de cette année, le score de 3:0 pour gagner le joueur chinois kija, AlphaGo a annoncé sa retraite, mais DeepMind n'a pas empêché le rythme de la recherche. Heure locale de Londres le 18 octobre, l'équipe de DeepMind a annoncé la version la plus forte de AlphaGo, nom de code AlphaGo Zero. ses tricheurs uniques, est "Self-autodidacte". En outre, dès le début d'un livre blanc, l'apprentissage à base zéro, en seulement 3 jours, devenant le maître supérieur.
L'équipe a dit, avant AlphaGo Zero a dépassé le niveau de toutes les versions de AlphaGo. ont gagné contre les joueurs sud-coréens Li, la version de AlphaGo, AlphaGo Zero 100:0 a atteint un succès écrasant. DeepMind équipe fera des recherches sur AlphaGo Zero sous la forme d'un papier, publié dans le 18 octobre "nature journal."
"dans les deux ans AlphaGo atteint étonnant." Maintenant, AlphaGo Zero est notre version la plus forte, il soulève beaucoup de. Zéro pour améliorer l'efficacité de calcul, et de ne pas utiliser de données d'échecs humains, "le père de la AlphaGo, DeepMind co-fondateur et PDG dèmes ha Sabis (Demis Hassabis) a dit," à la fin, nous voulons l'utiliser l'algorithme de percée, pour aider à résoudre le monde réel problèmes urgents, tels que le pliage de protéines ou de nouveaux matériaux de conception. «Si nous AlphaGo, pouvons faire des progrès sur ces questions, il a le potentiel de promouvoir la compréhension de la vie, et d'une manière positive d'affecter nos vies»
Ne sont plus limités par la connaissance humaine, seulement 4 TPU
AlphaGo la version précédente, avec des millions d'experts humains vont échecs, et de renforcer la supervision de l'apprentissage de l'autoformation.
Avant de vaincre le joueur professionnel de la Go, il est passé par des mois de formation, en s'appuyant sur plusieurs machines et 48 TPU (Google chips conçu pour accélérer le réseau neuronal Deep Computing)
AlphaGo Zero est une amélioration qualitative sur cette base. La plus grande différence est qu'il n'est plus nécessaire de données humaines. C'est à dire, il n'a pas de contact avec les échecs humains. Équipe de R & D il suffit de laisser libre de jouer aux échecs sur le plateau, puis Self Game. Il convient de mentionner que AlphaGo Zero est un "Low Carbon", d'utiliser une machine et 4 TPU, sauve considérablement les ressources.
AlphaGo Zero renforcement d'apprentissage sous le jeu d'échecs auto
Après quelques jours de formation, AlphaGo Zero terminé près de 5 millions Disc Self Game, peut aller au-delà de l'homme, et défait toutes les versions précédentes de l'AlphaGo DeepMind équipe a déclaré sur le blog officiel, avec le réseau neuronal mis à jour et des algorithmes de recherche de zéro recombinant, comme l'approfondissement de la formation, la performance du système un peu dans le progrès de soi. Les résultats du jeu sont de mieux en mieux, en même temps, le réseau neuronal est plus précis.
Le processus d'acquisition des connaissances par AlphaGo Zero
"la raison de ces détails techniques sont plus forts que la version précédente, nous n'avons plus les limites de la connaissance humaine, il peut apprendre à AlphaGo ses plus grands joueurs Go Field." AlphaGo Team Leader David Silva (Dave ruban) a dit.
Selon David Silva introduction, AlphaGo Zero utilise la nouvelle méthode d'apprentissage du renforcement, se laisser devenir l'enseignant. Ne sais même pas ce qu'est un système d'aller, juste à partir d'un seul réseau neuronal, l'algorithme de recherche de réseau neuronal est puissant, l'auto jouant aux échecs.
Avec l'augmentation du jeu de soi, le réseau neuronal est progressivement ajusté, améliorer la capacité prédictive de l'étape suivante, et finalement gagner le jeu. Plus puissant, avec une formation approfondie, l'équipe de DeepMind a constaté que AlphaGo Zero a également découvert indépendamment les règles du jeu, et hors de la nouvelle stratégie, apporter de nouvelles idées dans ce jeu d'échecs ancienne ronde.
Autodidacte pendant 3 jours, battre l'ancienne version de AlphaGo
"la raison de ces détails techniques sont plus forts que la version précédente, nous n'avons plus les limites de la connaissance humaine, il peut apprendre à AlphaGo ses plus grands joueurs Go Field." AlphaGo Team Leader David Silva (Dave ruban) a dit.
Selon David Silva introduction, AlphaGo Zero utilise la nouvelle méthode d'apprentissage du renforcement, se laisser devenir l'enseignant. Ne sais même pas ce qu'est un système d'aller, juste à partir d'un seul réseau neuronal, l'algorithme de recherche de réseau neuronal est puissant, l'auto jouant aux échecs.
Avec l'augmentation du jeu de soi, le réseau neuronal est progressivement ajusté, améliorer la capacité prédictive de l'étape suivante, et finalement gagner le jeu. Plus puissant, avec une formation approfondie, l'équipe de DeepMind a constaté que AlphaGo Zero a également découvert indépendamment les règles du jeu, et hors de la nouvelle stratégie, apporter de nouvelles idées dans ce jeu d'échecs ancienne ronde.
Autodidacte pendant 3 jours, battre l'ancienne version de AlphaGo
En plus des différences ci-dessus, AlphaGo zéro en 3 aspects par rapport à la version précédente a une différence évidente
L'axe de temps de formation de AlphaGo-Zero
D'abord, AlphaGo Zero utilise uniquement le noir et blanc sur l'échiquier comme entrée, tandis que le premier comprend un petit nombre d'entrées de fonctionnalités artificiellement conçues
Deuxièmement, AlphaGo Zero n'utilise qu'un seul réseau neuronal. Dans les versions précédentes, le AlphaGo utilise la stratégie de «réseau» pour choisir le prochain mouvement, et l'utilisation du «réseau de valeur» pour prévoir chaque étape après le vainqueur. Mais dans la nouvelle version, le réseau neuronal deux peut être fait un. Il peut obtenir la formation et l'évaluation plus efficace.
Troisièmement, AlphaGo Zero n'utilise pas la méthode de marche rapide et aléatoire. Dans les versions précédentes, AlphaGo est rapide méthode de marche pour prédire quel joueur de jeu va gagner le jeu de la situation actuelle. Au contraire, la nouvelle version est de s'appuyer sur la haute qualité du réseau neuronal pour évaluer la situation du jeu.
AlphaGo plusieurs versions du classement
Selon le Kazakhstan Biscaye et Silva introduction, ces différentes versions d'aide de AlphaGo s'est améliorée dans le système, et le changement de l'algorithme de rendre le système de devenir plus fort et plus efficace.
Après seulement 3 jours de self training, AlphaGo Zero sur la forte bat la victoire précédente sur Li-chicha dans l'ancienne version de AlphaGo, ils sont 100:0. Après 40 jours de self training, AlphaGo Zero Beat AlphaGo Master version. "Master" battre les meilleurs joueurs du monde, même y compris kija classé premier dans le monde.
Pour promouvoir le progrès de la société humaine en utilisant l'intelligence artificielle DeepMind mission, l'ultime AlphaGo n'est pas allé, leur but a été d'utiliser AlphaGo pour créer un général, d'explorer les outils ultimes de l'univers de. L'ascension de AlphaGo Zero, laissez DeepMind voir un changement dans le destin de l'humanité en utilisant la percée de technologie de l'intelligence artificielle. Ils sont actuellement actifs et les institutions médicales britanniques et la coopération du secteur de l'énergie électrique, améliorent l'efficacité du traitement et l'efficacité énergétique.