























Alfa Dog Evolution: studio di auto 3 giorni 100:0 Rolling li-versione del vecchio cane
chinatopwin
chinatopwin
2017-10-19 09:55:03
Ora locale di Londra a 18:00 il 18 ottobre (tempo di Pechino 19 01:00), AlphaGo ancora sulla natura scientifica superiore del giornale del mondo. "
Più di un anno fa, AlphaGo è un articolo di copertura nel periodo 28 gennaio 2016, Deepmind rilasciato un documento pesante, ha introdotto questo battere il campionato europeo di scacchi fan Hui programma di intelligenza artificiale.
Nel maggio di quest'anno, il Punteggio di 3:0 per vincere il giocatore cinese Giovanna, AlphaGo annunciato il suo pensionamento, ma DeepMind non ha fermato il ritmo di ricerca. Ora locale di Londra il 18 ottobre, il team di DeepMind ha annunciato la versione più forte di AlphaGo, nome in AlphaGo zero. i suoi trucchi unici, è "self-autodidatta". Inoltre, dall'inizio di un libro bianco, zero apprendimento basato, in soli 3 giorni, diventando il top master.
La squadra ha detto, prima AlphaGo zero ha superato il livello di tutte le versioni di AlphaGo. hanno vinto contro il sud coreano giocatori li la versione di AlphaGo, AlphaGo zero 100:0 ha raggiunto il successo travolgente. DeepMind team ricercherà su AlphaGo zero sotto forma di un documento, pubblicato nel 18 ottobre "Nature Journal.
"entro due anni AlphaGo raggiunto incredibile. Ora, AlphaGo zero è la nostra versione più forte, si solleva un sacco di. Zero per migliorare l'efficienza computazionale, e di non utilizzare alcun dato di scacchi umani, "il padre del AlphaGo, DeepMind co-fondatore e CEO Alessio ha Sabis (Demis Hassabis) ha detto," alla fine, vogliamo usarlo l'algoritmo di svolta, per aiutare a risolvere il mondo reale problemi urgenti, come la proteina pieghevole o progettare nuovi materiali. Se ci AlphaGo, può fare progressi su questi temi, ha il potenziale per promuovere la comprensione della vita, e in un modo positivo per influenzare la nostra vita "
Non più limitata dalla conoscenza umana, solo 4 TPU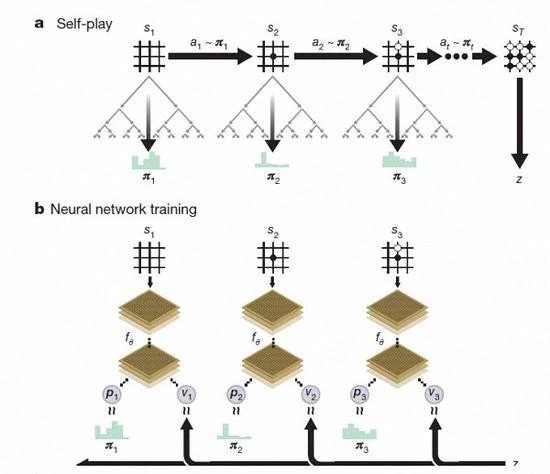
AlphaGo la versione precedente, con milioni di esperti umani andare a scacchi, e rafforzare la supervisione di apprendimento di auto-formazione.
Prima di sconfiggere il giocatore professionista del Go, è passato attraverso mesi di formazione, affidandosi a più macchine e 48 TPU (Google chips progettato per velocizzare Deep Neural Network Computing)
AlphaGo zero è un miglioramento qualitativo su questa base. La differenza più grande è che non è più necessario per i dati umani. Vale a dire, non ha alcun contatto con scacchi umani. Team R & D basta lasciarlo libero di giocare a scacchi sul tabellone, e poi gioco di auto. Vale la pena ricordare che AlphaGo zero è un "Low Carbon", di utilizzare una macchina e 4 TPU, Risparmia notevolmente le risorse.
AlphaGo zero rinforzo apprendimento sotto il gioco di scacchi di auto
Dopo pochi giorni di formazione, AlphaGo zero completato quasi 5 milioni disco auto gioco, può andare oltre l'uomo, e sconfitto tutte le versioni precedenti del AlphaGo. DeepMind team ha detto sul Blog ufficiale, con la rete neurale aggiornata e algoritmi di ricerca di ricombinante zero, come la formazione approfondisce, le prestazioni del sistema un po' in auto-progresso. I risultati del gioco sono sempre meglio, allo stesso tempo, la rete neurale è più preciso.
Oltre alle differenze di cui sopra, AlphaGo zero in 3 aspetti rispetto alla versione precedente ha ovvia differenza
L'asse di tempo di addestramento di AlphaGo-zero
In primo luogo, AlphaGo zero utilizza solo in bianco e nero sulla scacchiera come input, mentre il primo include un piccolo numero di ingressi caratteristica artificialmente progettato
In secondo luogo, AlphaGo zero utilizza solo una singola rete neurale. Nelle versioni precedenti, il AlphaGo utilizza la strategia di "rete" per scegliere la prossima mossa, e l'uso di "rete di valore" per prevedere ogni passo dopo il vincitore. Ma nella nuova versione, la rete neurale due può essere fatto uno. Si può ottenere la formazione e la valutazione più efficiente.
In terzo luogo, AlphaGo zero non utilizza il metodo di camminata veloce e casuale. Nelle versioni precedenti, AlphaGo è veloce metodo a piedi per prevedere quale giocatore vincerà il gioco dalla situazione attuale. Al contrario, la nuova versione è affidarsi all'alta qualità della rete neurale per valutare la situazione del gioco.
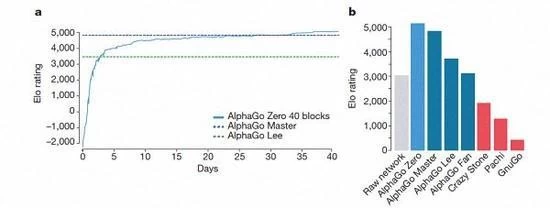
AlphaGo diverse versioni della classifica
Secondo Kazakhstan Biscaglia e Silva introduzione, queste diverse versioni di aiuto di AlphaGo è migliorata nel sistema, e il cambiamento dell'algoritmo di rendere il sistema di diventare più forte e più efficace.
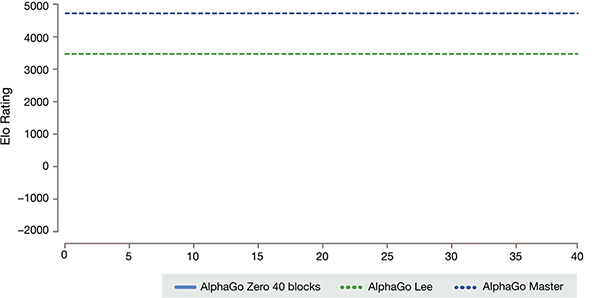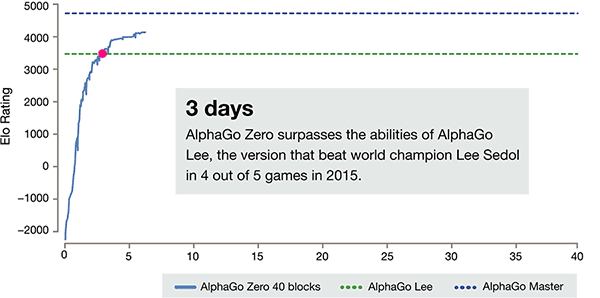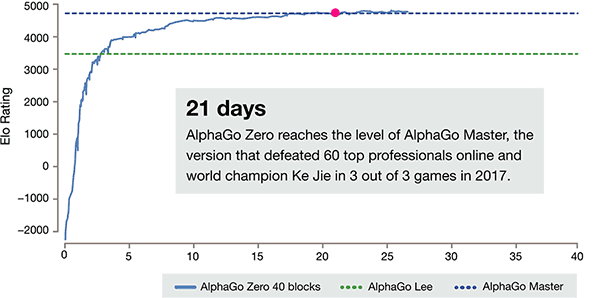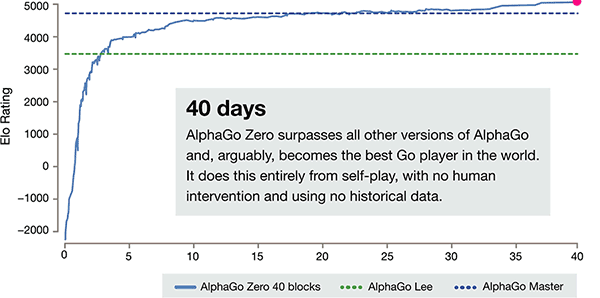
Dopo soli 3 giorni di auto-formazione, AlphaGo zero sul forte batte la vittoria precedente su di li, nella vecchia versione di AlphaGo, sono 100:0. Dopo 40 giorni di auto-formazione, AlphaGo zero Beat AlphaGo versione master. "Master" battere i migliori giocatori del mondo, anche tra cui Giovanna classificato primo al mondo.
Per promuovere il progresso della società umana utilizzando intelligenza artificiale DeepMind missione, l'ultimo AlphaGo non è andato, il loro obiettivo è stato quello di utilizzare AlphaGo per creare un generale, esplorare gli strumenti definitivi dell'universo di. Ascensione di AlphaGo zero, lasci DeepMind vedere un cambiamento nel destino dell'umanità usando l'innovazione di tecnologia di intelligenza artificiale. Sono attualmente attivi e le istituzioni mediche britanniche e la cooperazione del settore energia energetica, migliorare l'efficienza di trattamento e l'efficienza energetica.
Più di un anno fa, AlphaGo è un articolo di copertura nel periodo 28 gennaio 2016, Deepmind rilasciato un documento pesante, ha introdotto questo battere il campionato europeo di scacchi fan Hui programma di intelligenza artificiale.
Nel maggio di quest'anno, il Punteggio di 3:0 per vincere il giocatore cinese Giovanna, AlphaGo annunciato il suo pensionamento, ma DeepMind non ha fermato il ritmo di ricerca. Ora locale di Londra il 18 ottobre, il team di DeepMind ha annunciato la versione più forte di AlphaGo, nome in AlphaGo zero. i suoi trucchi unici, è "self-autodidatta". Inoltre, dall'inizio di un libro bianco, zero apprendimento basato, in soli 3 giorni, diventando il top master.
La squadra ha detto, prima AlphaGo zero ha superato il livello di tutte le versioni di AlphaGo. hanno vinto contro il sud coreano giocatori li la versione di AlphaGo, AlphaGo zero 100:0 ha raggiunto il successo travolgente. DeepMind team ricercherà su AlphaGo zero sotto forma di un documento, pubblicato nel 18 ottobre "Nature Journal.
"entro due anni AlphaGo raggiunto incredibile. Ora, AlphaGo zero è la nostra versione più forte, si solleva un sacco di. Zero per migliorare l'efficienza computazionale, e di non utilizzare alcun dato di scacchi umani, "il padre del AlphaGo, DeepMind co-fondatore e CEO Alessio ha Sabis (Demis Hassabis) ha detto," alla fine, vogliamo usarlo l'algoritmo di svolta, per aiutare a risolvere il mondo reale problemi urgenti, come la proteina pieghevole o progettare nuovi materiali. Se ci AlphaGo, può fare progressi su questi temi, ha il potenziale per promuovere la comprensione della vita, e in un modo positivo per influenzare la nostra vita "
Non più limitata dalla conoscenza umana, solo 4 TPU
AlphaGo la versione precedente, con milioni di esperti umani andare a scacchi, e rafforzare la supervisione di apprendimento di auto-formazione.
Prima di sconfiggere il giocatore professionista del Go, è passato attraverso mesi di formazione, affidandosi a più macchine e 48 TPU (Google chips progettato per velocizzare Deep Neural Network Computing)
AlphaGo zero è un miglioramento qualitativo su questa base. La differenza più grande è che non è più necessario per i dati umani. Vale a dire, non ha alcun contatto con scacchi umani. Team R & D basta lasciarlo libero di giocare a scacchi sul tabellone, e poi gioco di auto. Vale la pena ricordare che AlphaGo zero è un "Low Carbon", di utilizzare una macchina e 4 TPU, Risparmia notevolmente le risorse.
AlphaGo zero rinforzo apprendimento sotto il gioco di scacchi di auto
Dopo pochi giorni di formazione, AlphaGo zero completato quasi 5 milioni disco auto gioco, può andare oltre l'uomo, e sconfitto tutte le versioni precedenti del AlphaGo. DeepMind team ha detto sul Blog ufficiale, con la rete neurale aggiornata e algoritmi di ricerca di ricombinante zero, come la formazione approfondisce, le prestazioni del sistema un po' in auto-progresso. I risultati del gioco sono sempre meglio, allo stesso tempo, la rete neurale è più preciso.
Il processo di acquisizione della conoscenza da AlphaGo zero
"la ragione per cui questi dettagli tecnici sono più forti della versione precedente, non abbiamo più i limiti della conoscenza umana, può imparare a AlphaGo i suoi più alti giocatori go Field." AlphaGo team leader David Silva (Dave scheggia) ha detto.
Secondo David Silva introduzione, AlphaGo zero utilizza il nuovo metodo di apprendimento di rinforzo, lasciarsi diventare l'insegnante. Non so nemmeno che cosa un sistema di andare, solo da una singola rete neurale, l'algoritmo di ricerca di rete neurale è potente, il gioco di sé scacchi.
Con l'aumento del gioco di auto, la rete neurale è registrata gradualmente, aumentano la capacità predittiva del punto seguente e infine vincono il gioco. Più potente, con una formazione approfondita, il team DeepMind trovato che AlphaGo zero anche indipendentemente scoperto le regole del gioco, e fuori della nuova strategia, portare nuove intuizioni in questo antico gioco di scacchi rotondo.
Self Study per 3 giorni, battere la vecchia versione di AlphaGo
"la ragione per cui questi dettagli tecnici sono più forti della versione precedente, non abbiamo più i limiti della conoscenza umana, può imparare a AlphaGo i suoi più alti giocatori go Field." AlphaGo team leader David Silva (Dave scheggia) ha detto.
Secondo David Silva introduzione, AlphaGo zero utilizza il nuovo metodo di apprendimento di rinforzo, lasciarsi diventare l'insegnante. Non so nemmeno che cosa un sistema di andare, solo da una singola rete neurale, l'algoritmo di ricerca di rete neurale è potente, il gioco di sé scacchi.
Con l'aumento del gioco di auto, la rete neurale è registrata gradualmente, aumentano la capacità predittiva del punto seguente e infine vincono il gioco. Più potente, con una formazione approfondita, il team DeepMind trovato che AlphaGo zero anche indipendentemente scoperto le regole del gioco, e fuori della nuova strategia, portare nuove intuizioni in questo antico gioco di scacchi rotondo.
Self Study per 3 giorni, battere la vecchia versione di AlphaGo
Oltre alle differenze di cui sopra, AlphaGo zero in 3 aspetti rispetto alla versione precedente ha ovvia differenza
L'asse di tempo di addestramento di AlphaGo-zero
In primo luogo, AlphaGo zero utilizza solo in bianco e nero sulla scacchiera come input, mentre il primo include un piccolo numero di ingressi caratteristica artificialmente progettato
In secondo luogo, AlphaGo zero utilizza solo una singola rete neurale. Nelle versioni precedenti, il AlphaGo utilizza la strategia di "rete" per scegliere la prossima mossa, e l'uso di "rete di valore" per prevedere ogni passo dopo il vincitore. Ma nella nuova versione, la rete neurale due può essere fatto uno. Si può ottenere la formazione e la valutazione più efficiente.
In terzo luogo, AlphaGo zero non utilizza il metodo di camminata veloce e casuale. Nelle versioni precedenti, AlphaGo è veloce metodo a piedi per prevedere quale giocatore vincerà il gioco dalla situazione attuale. Al contrario, la nuova versione è affidarsi all'alta qualità della rete neurale per valutare la situazione del gioco.
AlphaGo diverse versioni della classifica
Secondo Kazakhstan Biscaglia e Silva introduzione, queste diverse versioni di aiuto di AlphaGo è migliorata nel sistema, e il cambiamento dell'algoritmo di rendere il sistema di diventare più forte e più efficace.
Dopo soli 3 giorni di auto-formazione, AlphaGo zero sul forte batte la vittoria precedente su di li, nella vecchia versione di AlphaGo, sono 100:0. Dopo 40 giorni di auto-formazione, AlphaGo zero Beat AlphaGo versione master. "Master" battere i migliori giocatori del mondo, anche tra cui Giovanna classificato primo al mondo.
Per promuovere il progresso della società umana utilizzando intelligenza artificiale DeepMind missione, l'ultimo AlphaGo non è andato, il loro obiettivo è stato quello di utilizzare AlphaGo per creare un generale, esplorare gli strumenti definitivi dell'universo di. Ascensione di AlphaGo zero, lasci DeepMind vedere un cambiamento nel destino dell'umanità usando l'innovazione di tecnologia di intelligenza artificiale. Sono attualmente attivi e le istituzioni mediche britanniche e la cooperazione del settore energia energetica, migliorare l'efficienza di trattamento e l'efficienza energetica.