























Evolução do cão alfa: estudo de auto 3 dias 100:0 Rolling li shish versão do cão velho
chinatopwin
chinatopwin
2017-10-19 09:55:03
Londres hora local em 18:00 em 18 de outubro (Pequim tempo 19 01:00), AlphaGo novamente sobre a natureza do mundo revista científica Top. "
Mais de um ano atrás, AlphaGo é um artigo de capa no período de 28 de janeiro de 2016, Deepmind emitiu um papel pesado, introduziu esta batida do Campeonato Europeu de xadrez Fan Hui programa de inteligência artificial.
Em maio deste ano, a pontuação de 3:0 para ganhar o jogador chinês Kija, AlphaGo anunciou sua aposentadoria, mas DeepMind não parou o ritmo da pesquisa. Londres hora local em 18 de outubro, a equipe DeepMind anunciou a versão mais forte de AlphaGo, codenamed AlphaGo zero. suas fraudes originais, são Self-autodidata. Além disso, desde o início de um livro branco, zero aprendizagem baseada, em apenas 3 dias, tornando-se o mestre superior.
A equipe disse, antes AlphaGo zero ultrapassou o nível de todas as versões do AlphaGo. ganharam contra os jogadores sul-coreanos Li Shishi versão de AlphaGo, AlphaGo zero 100:0 alcançou sucesso esmagadora. DeepMind equipe irá pesquisar sobre AlphaGo zero na forma de um papel, publicado no dia 18 de outubro "Nature Journal.
"dentro de dois anos AlphaGo alcançado surpreendente. Agora, AlphaGo zero é a nossa versão mais forte, ele levanta um monte de. Zero para melhorar a eficiência computacional, e não usar quaisquer dados de xadrez humano, "o pai do AlphaGo, DeepMind co-fundador e CEO demos ha Sabis (Demis Hassabis) disse:" no final, queremos usá-lo o algoritmo de descoberta, para ajudar a resolver o mundo real problemas urgentes, tais como a dobradura da proteína ou projetam materiais novos. Se nós AlphaGo, pode fazer progressos sobre estas questões, tem o potencial para promover a compreensão da vida, e de uma forma positiva para afetar nossas vidas "
Não mais limitado pelo conhecimento humano, apenas 4 TPU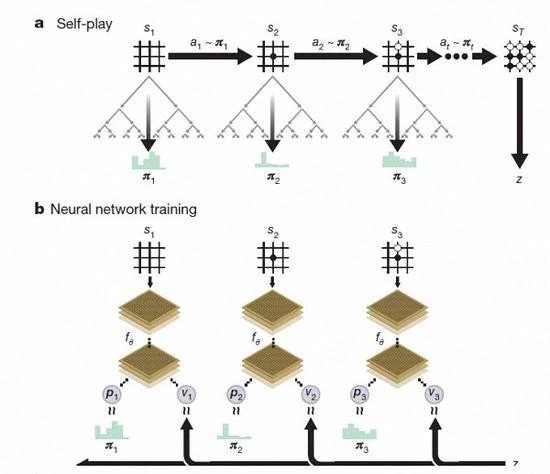
AlphaGo a versão anterior, com milhões de peritos humanos ir xadrez, e fortalecer a supervisão da aprendizagem de treinamento de auto.
Antes de derrotar o jogador profissional do Go, ele passou por meses de treinamento, contando com várias máquinas e 48 TPU (Google chips projetados para acelerar a computação de rede neural profunda)
AlphaGo zero é uma melhoria qualitativa nesta base. A diferença a mais grande é que não é mais necessário aos dados humanos. Quer dizer, não tem contato com o xadrez humano. R & D equipe apenas deixá-lo livre para jogar xadrez no tabuleiro, e depois jogo Self. Vale a pena mencionar que AlphaGo zero é um "baixo carbono", para usar uma máquina e 4 TPU, economiza muito recursos.
AlphaGo zero reforço aprendizagem o jogo de xadrez Self
Depois de alguns dias de treinamento, AlphaGo zero completou quase 5 milhões disco Self Game, pode ir além do ser humano, e derrotou todas as versões anteriores do AlphaGo. DeepMind equipe disse no blog oficial, com a rede neural atualizado e algoritmos de busca de Zero recombinante, como o treinamento se aprofunda, o desempenho do sistema um pouco em auto progresso. Os resultados do jogo estão ficando cada vez melhor, ao mesmo tempo, a rede neural é mais preciso.
Além das diferenças acima, AlphaGo zero em 3 aspectos em comparação com a versão anterior tem diferença óbvia
O eixo do tempo de treinamento de AlphaGo-zero
Primeiro, AlphaGo zero só usa preto e branco no tabuleiro de xadrez como entrada, enquanto o primeiro inclui um pequeno número de insumos de recurso artificialmente projetados
Em segundo lugar, AlphaGo zero usa apenas uma rede neural única. Em versões anteriores, o AlphaGo usa a estratégia de "rede" para escolher o próximo movimento, e o uso de "rede de valor" para prever cada etapa após o vencedor. Mas na nova versão, as duas redes neurais podem ser feitas uma. Ele pode obter o treinamento e avaliação mais eficiente.
Terceiro, AlphaGo zero não usa o método de caminhada rápida e aleatória. Em versões anteriores, AlphaGo é método de caminhada rápida para prever qual jogador vai ganhar o jogo a partir da situação atual. Pelo contrário, a nova versão é contar com a alta qualidade da rede neural para avaliar a situação do jogo.
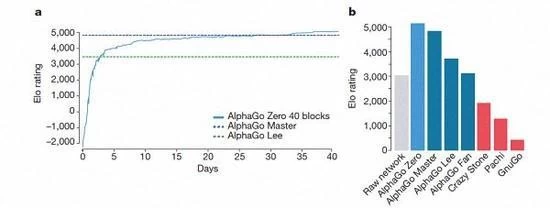
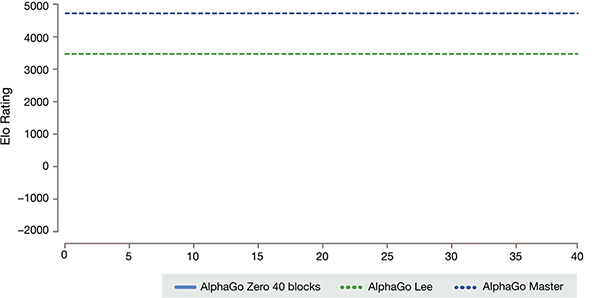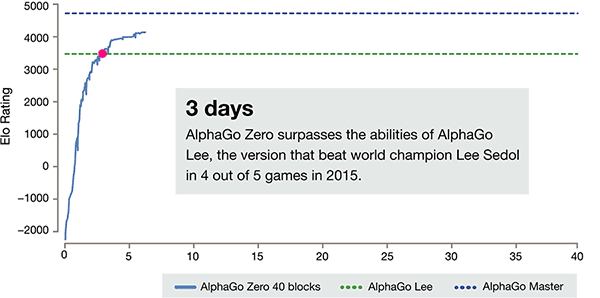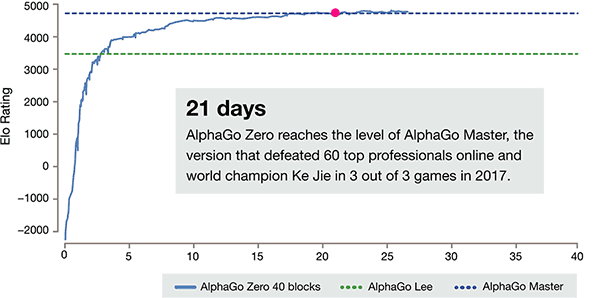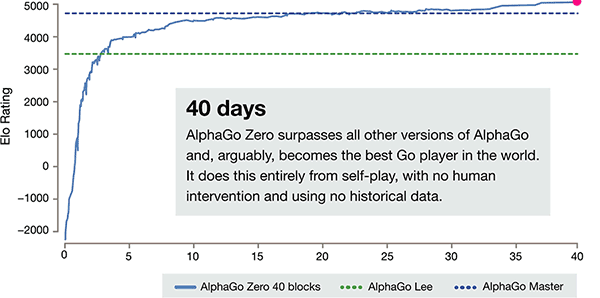
AlphaGo várias versões dos rankings
De acordo com o Cazaquistão Vizcaya e Silva introdução, estas diferentes ajuda versão do AlphaGo melhorou no sistema, ea mudança do algoritmo fazer o sistema para se tornar mais forte e mais eficaz.
Depois de apenas 3 dias de treinamento de auto, AlphaGo zero sobre o forte bate a vitória anterior sobre Li Shishi na versão antiga do AlphaGo, eles são 100:0. Após 40 dias de treinamento de auto, AlphaGo zero Beat AlphaGo versão Master. "Master" vencer os melhores jogadores do mundo, mesmo incluindo Kija classificado em primeiro lugar no mundo.
Para promover o progresso da sociedade humana usando inteligência artificial DeepMind missão, o AlphaGo final não ir, seu objetivo foi usar AlphaGo para criar um General, explorar as ferramentas finais do universo de. A ascensão de AlphaGo zero, deixe DeepMind ver uma mudança no destino da humanidade usando o avanço da tecnologia de inteligência artificial. Estão actualmente activas e as instituições médicas britânicas e a cooperação no sector da energia energética, melhoram a eficiência do tratamento e a eficiência energética.
Mais de um ano atrás, AlphaGo é um artigo de capa no período de 28 de janeiro de 2016, Deepmind emitiu um papel pesado, introduziu esta batida do Campeonato Europeu de xadrez Fan Hui programa de inteligência artificial.
Em maio deste ano, a pontuação de 3:0 para ganhar o jogador chinês Kija, AlphaGo anunciou sua aposentadoria, mas DeepMind não parou o ritmo da pesquisa. Londres hora local em 18 de outubro, a equipe DeepMind anunciou a versão mais forte de AlphaGo, codenamed AlphaGo zero. suas fraudes originais, são Self-autodidata. Além disso, desde o início de um livro branco, zero aprendizagem baseada, em apenas 3 dias, tornando-se o mestre superior.
A equipe disse, antes AlphaGo zero ultrapassou o nível de todas as versões do AlphaGo. ganharam contra os jogadores sul-coreanos Li Shishi versão de AlphaGo, AlphaGo zero 100:0 alcançou sucesso esmagadora. DeepMind equipe irá pesquisar sobre AlphaGo zero na forma de um papel, publicado no dia 18 de outubro "Nature Journal.
"dentro de dois anos AlphaGo alcançado surpreendente. Agora, AlphaGo zero é a nossa versão mais forte, ele levanta um monte de. Zero para melhorar a eficiência computacional, e não usar quaisquer dados de xadrez humano, "o pai do AlphaGo, DeepMind co-fundador e CEO demos ha Sabis (Demis Hassabis) disse:" no final, queremos usá-lo o algoritmo de descoberta, para ajudar a resolver o mundo real problemas urgentes, tais como a dobradura da proteína ou projetam materiais novos. Se nós AlphaGo, pode fazer progressos sobre estas questões, tem o potencial para promover a compreensão da vida, e de uma forma positiva para afetar nossas vidas "
Não mais limitado pelo conhecimento humano, apenas 4 TPU
AlphaGo a versão anterior, com milhões de peritos humanos ir xadrez, e fortalecer a supervisão da aprendizagem de treinamento de auto.
Antes de derrotar o jogador profissional do Go, ele passou por meses de treinamento, contando com várias máquinas e 48 TPU (Google chips projetados para acelerar a computação de rede neural profunda)
AlphaGo zero é uma melhoria qualitativa nesta base. A diferença a mais grande é que não é mais necessário aos dados humanos. Quer dizer, não tem contato com o xadrez humano. R & D equipe apenas deixá-lo livre para jogar xadrez no tabuleiro, e depois jogo Self. Vale a pena mencionar que AlphaGo zero é um "baixo carbono", para usar uma máquina e 4 TPU, economiza muito recursos.
AlphaGo zero reforço aprendizagem o jogo de xadrez Self
Depois de alguns dias de treinamento, AlphaGo zero completou quase 5 milhões disco Self Game, pode ir além do ser humano, e derrotou todas as versões anteriores do AlphaGo. DeepMind equipe disse no blog oficial, com a rede neural atualizado e algoritmos de busca de Zero recombinante, como o treinamento se aprofunda, o desempenho do sistema um pouco em auto progresso. Os resultados do jogo estão ficando cada vez melhor, ao mesmo tempo, a rede neural é mais preciso.
O processo de aquisição de conhecimento por AlphaGo zero
"a razão pela qual estes detalhes técnicos são mais fortes do que a versão anterior, nós já não temos os limites do conhecimento humano, ele pode aprender a AlphaGo seus jogadores mais altos vão campo." AlphaGo equipe líder David Silva (Dave Fractius) disse.
De acordo com David Silva introdução, AlphaGo zero usa o novo método de aprendizado de reforço, deixe-se tornar o professor. Não sei mesmo o que um sistema para ir, apenas a partir de uma única rede neural, o algoritmo de busca de rede neural é poderoso, o Self jogando xadrez.
Com o aumento do jogo do self, a rede neural é ajustada gradualmente, realça a habilidade preditiva da etapa seguinte, e ganha finalmente o jogo. Mais poderoso, com treinamento em profundidade, a equipe DeepMind descobriu que AlphaGo zero também independente descobriu as regras do jogo, e fora da nova estratégia, trazer novas idéias sobre este jogo de xadrez antigo round.
Auto-estudo por 3 dias, bater a versão antiga do AlphaGo
"a razão pela qual estes detalhes técnicos são mais fortes do que a versão anterior, nós já não temos os limites do conhecimento humano, ele pode aprender a AlphaGo seus jogadores mais altos vão campo." AlphaGo equipe líder David Silva (Dave Fractius) disse.
De acordo com David Silva introdução, AlphaGo zero usa o novo método de aprendizado de reforço, deixe-se tornar o professor. Não sei mesmo o que um sistema para ir, apenas a partir de uma única rede neural, o algoritmo de busca de rede neural é poderoso, o Self jogando xadrez.
Com o aumento do jogo do self, a rede neural é ajustada gradualmente, realça a habilidade preditiva da etapa seguinte, e ganha finalmente o jogo. Mais poderoso, com treinamento em profundidade, a equipe DeepMind descobriu que AlphaGo zero também independente descobriu as regras do jogo, e fora da nova estratégia, trazer novas idéias sobre este jogo de xadrez antigo round.
Auto-estudo por 3 dias, bater a versão antiga do AlphaGo
Além das diferenças acima, AlphaGo zero em 3 aspectos em comparação com a versão anterior tem diferença óbvia
O eixo do tempo de treinamento de AlphaGo-zero
Primeiro, AlphaGo zero só usa preto e branco no tabuleiro de xadrez como entrada, enquanto o primeiro inclui um pequeno número de insumos de recurso artificialmente projetados
Em segundo lugar, AlphaGo zero usa apenas uma rede neural única. Em versões anteriores, o AlphaGo usa a estratégia de "rede" para escolher o próximo movimento, e o uso de "rede de valor" para prever cada etapa após o vencedor. Mas na nova versão, as duas redes neurais podem ser feitas uma. Ele pode obter o treinamento e avaliação mais eficiente.
Terceiro, AlphaGo zero não usa o método de caminhada rápida e aleatória. Em versões anteriores, AlphaGo é método de caminhada rápida para prever qual jogador vai ganhar o jogo a partir da situação atual. Pelo contrário, a nova versão é contar com a alta qualidade da rede neural para avaliar a situação do jogo.
AlphaGo várias versões dos rankings
De acordo com o Cazaquistão Vizcaya e Silva introdução, estas diferentes ajuda versão do AlphaGo melhorou no sistema, ea mudança do algoritmo fazer o sistema para se tornar mais forte e mais eficaz.
Depois de apenas 3 dias de treinamento de auto, AlphaGo zero sobre o forte bate a vitória anterior sobre Li Shishi na versão antiga do AlphaGo, eles são 100:0. Após 40 dias de treinamento de auto, AlphaGo zero Beat AlphaGo versão Master. "Master" vencer os melhores jogadores do mundo, mesmo incluindo Kija classificado em primeiro lugar no mundo.
Para promover o progresso da sociedade humana usando inteligência artificial DeepMind missão, o AlphaGo final não ir, seu objetivo foi usar AlphaGo para criar um General, explorar as ferramentas finais do universo de. A ascensão de AlphaGo zero, deixe DeepMind ver uma mudança no destino da humanidade usando o avanço da tecnologia de inteligência artificial. Estão actualmente activas e as instituições médicas britânicas e a cooperação no sector da energia energética, melhoram a eficiência do tratamento e a eficiência energética.