























Ewolucja pies alfa: Self Study 3 dni 100: 0 toczenia Li Shishi wersja starego psa
chinatopwin
chinatopwin
2017-10-19 09:55:03
Czas lokalny Londyn 18 października 18:00 (czasu pekińskiego 19 01:00), AlphaGo ponownie na najlepsze czasopismo naukowe na świecie natury. "
Ponad rok temu, AlphaGo jest artykuł okładka w okresie styczeń 28, 2016, Deepmind wydane Gruby papier, wprowadzone to pokonać program sztucznej inteligencji Hui fan Mistrzostwa Europy w szachach.
W maju tego roku, wynik 3:0, aby wygrać chiński odtwarzacz kija, AlphaGo ogłosił zakończenie kariery, ale DeepMind nie zatrzymał tempo badań. Czas lokalny na 18 października Londyn, DeepMind zespół ogłosił najsilniejszej wersji AlphaGo, o nazwie kodowej AlphaGo Zero. jego unikalne kody, "siebie samoukiem". Ponadto od początku białą księgę, na podstawie zero nauki, w ciągu zaledwie 3 dni, staje się top master.
Zespół powiedział, zanim AlphaGo Zero przekroczył poziom wszystkie wersje AlphaGo. wygrali przeciwko Korei Południowej graczy Li Shishi wersja AlphaGo, AlphaGo Zero 100: 0 osiągnęła sukces przytłaczające. DeepMind zespół badania będą na AlphaGo Zero w formularzu opublikowanym w 18 października "charakter urzędowy.
"W ciągu dwóch lat AlphaGo osiągnąć niesamowite. Teraz AlphaGo Zero jest nasz najsilniejszy wersji, to rodzi wiele. Zero, aby poprawić efektywność obliczeniowa i nie używać żadnych danych żywe szachy,"ojca AlphaGo, DeepMind, współzałożyciel i CEO Demes Ha Sabis (Demis Hassabis) powiedział:"w końcu chcemy go używać algorytmu przełom, aby pomóc w rozwiązaniu rzeczywistych problemy pilne, takich jak białka składane lub projektowania nowych materiałów. Jeśli możemy AlphaGo, postępu w tych kwestiach, ma potencjał do wspierania zrozumienia życia i w pozytywny sposób wpływać na nasze życie"
Nie jest już ograniczony przez ludzkiej wiedzy, tylko 4 TPU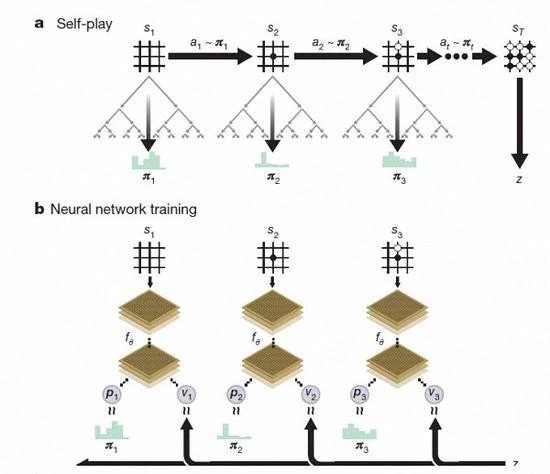
AlphaGo poprzedniej wersji, z milionami ludzi ekspertów przejdź szachy i wzmocnić nadzór nad nauka samodzielnego szkolenia.
Przed pokonując profesjonalny gracz go, przeszłam szkolenia, opierając się na wielu komputerach i 48 TPU (Google żetony przeznaczone do przyspieszenia głębokie Neural Network Computing)
AlphaGo Zero jest poprawa jakości na tej podstawie. Największą różnicą jest to, że już nie jest konieczne do danych ludzi. To znaczy ma żadnego kontaktu z żywe szachy. Zespół R & D to niech to darmowa gra szachy na pokładzie, a następnie własnej gry. Warto wspomnieć, że AlphaGo Zero jest "niskiej emisji dwutlenku węgla", aby użyć maszynę i 4 TPU, znacznie oszczędza zasoby.
Wzmocnienie AlphaGo Zero nauki pod siebie grać w szachy
Po kilku dniach szkolenia AlphaGo Zero zakończone prawie 5 milionów płyt self gra, może wykraczać poza człowieka i pokonał wszystkich poprzednich wersji Team AlphaGo.DeepMind powiedział na oficjalnym blogu, zaktualizowane neuronowe sieci i wyszukiwania algorytmów rekombinacji Zero, jak trening pogłębia, wydajność systemu trochę w siebie postępy. Wyniki gry są coraz lepiej i lepiej, w tym samym czasie, Sieć neuronowa jest bardziej dokładne.
Oprócz powyższych różnic AlphaGo Zero w 3 aspektach w porównaniu z poprzednią wersją ma oczywista różnica
Oś czasu szkolenia AlphaGo-zero
Po pierwsze AlphaGo Zero użyto tylko czarno-białe na szachownicy jako dane wejściowe, podczas gdy pierwsza zawiera niewielką liczbę sztucznie zaprojektowana funkcji wejść
Po drugie AlphaGo Zero używa tylko jednej sieci neuronowych. W poprzednich wersjach, AlphaGo zastosowania strategii "sieci", aby wybrać następny ruch i korzystanie z "wartość sieci" do Prognoza każdy krok po zwycięzcy. Ale w nowej wersji, można się dwóch sieci neuronowe jeden. Może dostać szkolenia i oceny bardziej efektywne.
Po trzecie AlphaGo Zero nie używać szybki, metody błądzenia losowego. W poprzednich wersjach AlphaGo jest metoda szybki spacer do przewidywania, która gra gracz wygra grę z obecnej sytuacji. Wręcz przeciwnie ten nowy wersja jest polegać na wysokiej jakości sieci neuronowych do oceny sytuacji w grze.
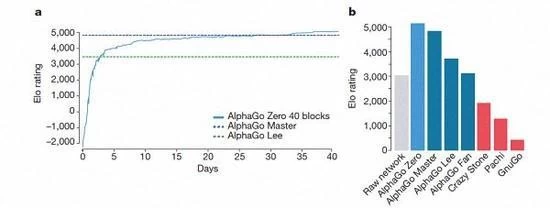
AlphaGo kilka wersji rankingi
Zgodnie z Kazachstanu Biskajskiej i Silva wprowadzenie tych wersji pomocy AlphaGo poprawiła się w systemie, i zmiana algorytmu zrobić ten system wobec stać się silniejsze i bardziej skuteczne.
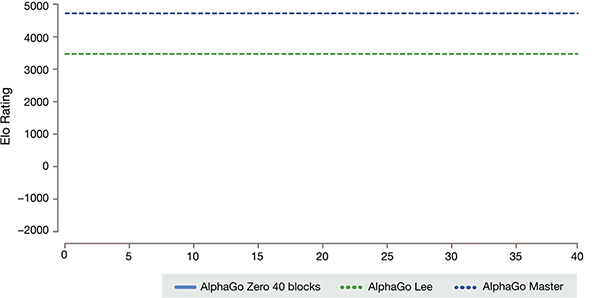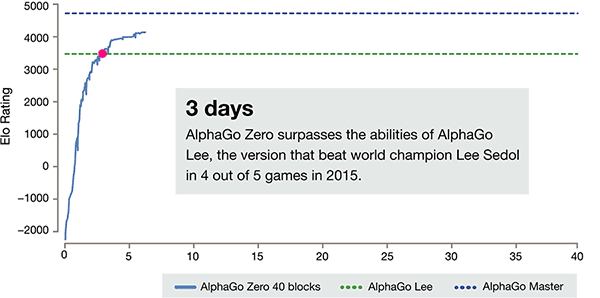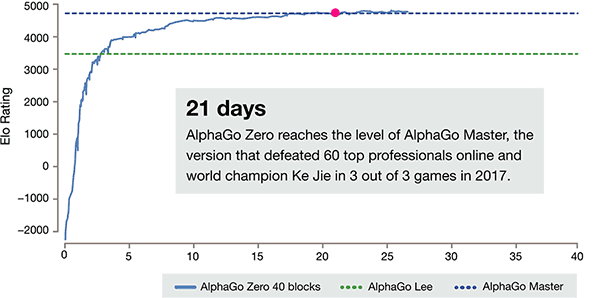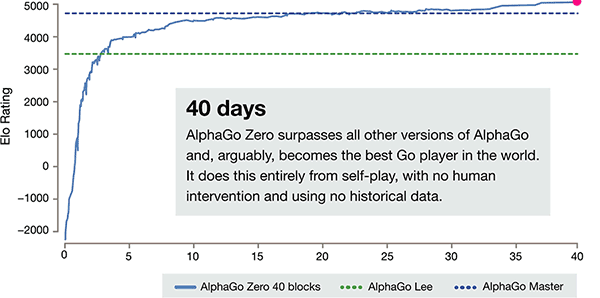
Po 3 dniach szkolenia siebie AlphaGo Zero na silne bije poprzednie zwycięstwa nad Li Shishi w starej wersji AlphaGo, są one 100: 0. Po 40 dniach samo szkolenia AlphaGo Zero pokonać mistrza AlphaGo wersji. "Master" pokonać najlepszych graczy na świecie, w tym nawet kija na pierwszym miejscu na świecie.
Wspieranie postępu ludzkiego społeczeństwa przy użyciu sztucznej inteligencji DeepMind misji, ultimate AlphaGo nie iść, ich celem ma był wobec używać AlphaGo, aby utworzyć ogólny, Poznaj ostatecznego narzędzia wszechświata z. AlphaGo Zero Wniebowstąpieniu, niech DeepMind zobaczyć zmiany w losy ludzkości przy użyciu przełomowej technologii sztucznej inteligencji. Są one obecnie aktywne i brytyjskiej instytucji medycznych i moc współpracy sektora energii, poprawić efektywność oczyszczania i efektywności energetycznej.
Ponad rok temu, AlphaGo jest artykuł okładka w okresie styczeń 28, 2016, Deepmind wydane Gruby papier, wprowadzone to pokonać program sztucznej inteligencji Hui fan Mistrzostwa Europy w szachach.
W maju tego roku, wynik 3:0, aby wygrać chiński odtwarzacz kija, AlphaGo ogłosił zakończenie kariery, ale DeepMind nie zatrzymał tempo badań. Czas lokalny na 18 października Londyn, DeepMind zespół ogłosił najsilniejszej wersji AlphaGo, o nazwie kodowej AlphaGo Zero. jego unikalne kody, "siebie samoukiem". Ponadto od początku białą księgę, na podstawie zero nauki, w ciągu zaledwie 3 dni, staje się top master.
Zespół powiedział, zanim AlphaGo Zero przekroczył poziom wszystkie wersje AlphaGo. wygrali przeciwko Korei Południowej graczy Li Shishi wersja AlphaGo, AlphaGo Zero 100: 0 osiągnęła sukces przytłaczające. DeepMind zespół badania będą na AlphaGo Zero w formularzu opublikowanym w 18 października "charakter urzędowy.
"W ciągu dwóch lat AlphaGo osiągnąć niesamowite. Teraz AlphaGo Zero jest nasz najsilniejszy wersji, to rodzi wiele. Zero, aby poprawić efektywność obliczeniowa i nie używać żadnych danych żywe szachy,"ojca AlphaGo, DeepMind, współzałożyciel i CEO Demes Ha Sabis (Demis Hassabis) powiedział:"w końcu chcemy go używać algorytmu przełom, aby pomóc w rozwiązaniu rzeczywistych problemy pilne, takich jak białka składane lub projektowania nowych materiałów. Jeśli możemy AlphaGo, postępu w tych kwestiach, ma potencjał do wspierania zrozumienia życia i w pozytywny sposób wpływać na nasze życie"
Nie jest już ograniczony przez ludzkiej wiedzy, tylko 4 TPU
AlphaGo poprzedniej wersji, z milionami ludzi ekspertów przejdź szachy i wzmocnić nadzór nad nauka samodzielnego szkolenia.
Przed pokonując profesjonalny gracz go, przeszłam szkolenia, opierając się na wielu komputerach i 48 TPU (Google żetony przeznaczone do przyspieszenia głębokie Neural Network Computing)
AlphaGo Zero jest poprawa jakości na tej podstawie. Największą różnicą jest to, że już nie jest konieczne do danych ludzi. To znaczy ma żadnego kontaktu z żywe szachy. Zespół R & D to niech to darmowa gra szachy na pokładzie, a następnie własnej gry. Warto wspomnieć, że AlphaGo Zero jest "niskiej emisji dwutlenku węgla", aby użyć maszynę i 4 TPU, znacznie oszczędza zasoby.
Wzmocnienie AlphaGo Zero nauki pod siebie grać w szachy
Po kilku dniach szkolenia AlphaGo Zero zakończone prawie 5 milionów płyt self gra, może wykraczać poza człowieka i pokonał wszystkich poprzednich wersji Team AlphaGo.DeepMind powiedział na oficjalnym blogu, zaktualizowane neuronowe sieci i wyszukiwania algorytmów rekombinacji Zero, jak trening pogłębia, wydajność systemu trochę w siebie postępy. Wyniki gry są coraz lepiej i lepiej, w tym samym czasie, Sieć neuronowa jest bardziej dokładne.
Proces zdobywania wiedzy przez AlphaGo Zero
"Dlatego te szczegóły techniczne są silniejsze niż w poprzedniej wersji, nie mamy już granice ludzkiej wiedzy, można nauczyć się AlphaGo, że jego najwyższy gracze go pola." Lider zespołu AlphaGo David Silva (Dave Sliver) powiedział.
Według wprowadzenie David Silva AlphaGo Zero używa nowego zbrojenia metoda nauczania, niech sobie stać się nauczycielem. Nawet nie wiem jaki system, aby przejść, tylko z jednej sieci neuronowych, Sieć neuronowa algorytm wyszukiwania jest potężny, self, gra w szachy.
Wraz ze wzrostem poczucie gry, neuronowe sieci jest stopniowo dostosowywać zwiększenia zdolności predykcyjnych następnego kroku i ostatecznie wygrać. Bardziej wydajne, szkolenia dogłębne, zespół DeepMind znaleźć, że AlphaGo Zero również niezależnie odkrył zasady gry, a spośród nowej strategii, wnieść nowe spojrzenie w tej starożytnej szachy rundy gry.
Samodzielnej nauki przez 3 dni, pokonać starej wersji AlphaGo
"Dlatego te szczegóły techniczne są silniejsze niż w poprzedniej wersji, nie mamy już granice ludzkiej wiedzy, można nauczyć się AlphaGo, że jego najwyższy gracze go pola." Lider zespołu AlphaGo David Silva (Dave Sliver) powiedział.
Według wprowadzenie David Silva AlphaGo Zero używa nowego zbrojenia metoda nauczania, niech sobie stać się nauczycielem. Nawet nie wiem jaki system, aby przejść, tylko z jednej sieci neuronowych, Sieć neuronowa algorytm wyszukiwania jest potężny, self, gra w szachy.
Wraz ze wzrostem poczucie gry, neuronowe sieci jest stopniowo dostosowywać zwiększenia zdolności predykcyjnych następnego kroku i ostatecznie wygrać. Bardziej wydajne, szkolenia dogłębne, zespół DeepMind znaleźć, że AlphaGo Zero również niezależnie odkrył zasady gry, a spośród nowej strategii, wnieść nowe spojrzenie w tej starożytnej szachy rundy gry.
Samodzielnej nauki przez 3 dni, pokonać starej wersji AlphaGo
Oprócz powyższych różnic AlphaGo Zero w 3 aspektach w porównaniu z poprzednią wersją ma oczywista różnica
Oś czasu szkolenia AlphaGo-zero
Po pierwsze AlphaGo Zero użyto tylko czarno-białe na szachownicy jako dane wejściowe, podczas gdy pierwsza zawiera niewielką liczbę sztucznie zaprojektowana funkcji wejść
Po drugie AlphaGo Zero używa tylko jednej sieci neuronowych. W poprzednich wersjach, AlphaGo zastosowania strategii "sieci", aby wybrać następny ruch i korzystanie z "wartość sieci" do Prognoza każdy krok po zwycięzcy. Ale w nowej wersji, można się dwóch sieci neuronowe jeden. Może dostać szkolenia i oceny bardziej efektywne.
Po trzecie AlphaGo Zero nie używać szybki, metody błądzenia losowego. W poprzednich wersjach AlphaGo jest metoda szybki spacer do przewidywania, która gra gracz wygra grę z obecnej sytuacji. Wręcz przeciwnie ten nowy wersja jest polegać na wysokiej jakości sieci neuronowych do oceny sytuacji w grze.
AlphaGo kilka wersji rankingi
Zgodnie z Kazachstanu Biskajskiej i Silva wprowadzenie tych wersji pomocy AlphaGo poprawiła się w systemie, i zmiana algorytmu zrobić ten system wobec stać się silniejsze i bardziej skuteczne.
Po 3 dniach szkolenia siebie AlphaGo Zero na silne bije poprzednie zwycięstwa nad Li Shishi w starej wersji AlphaGo, są one 100: 0. Po 40 dniach samo szkolenia AlphaGo Zero pokonać mistrza AlphaGo wersji. "Master" pokonać najlepszych graczy na świecie, w tym nawet kija na pierwszym miejscu na świecie.
Wspieranie postępu ludzkiego społeczeństwa przy użyciu sztucznej inteligencji DeepMind misji, ultimate AlphaGo nie iść, ich celem ma był wobec używać AlphaGo, aby utworzyć ogólny, Poznaj ostatecznego narzędzia wszechświata z. AlphaGo Zero Wniebowstąpieniu, niech DeepMind zobaczyć zmiany w losy ludzkości przy użyciu przełomowej technologii sztucznej inteligencji. Są one obecnie aktywne i brytyjskiej instytucji medycznych i moc współpracy sektora energii, poprawić efektywność oczyszczania i efektywności energetycznej.