






















Evolución de alfa Dog: auto estudio 3 días 100:0 Rolling Li Shishi versión del perro viejo
chinatopwin
chinatopwin
2017-10-19 09:55:03
Hora local de Londres en 18:00 el 18 de octubre (tiempo de Pekín 19 01:00), AlphaGo otra vez en la revista científica más alta del mundo naturaleza. "
Hace más de un año, AlphaGo es un artículo de portada en el período 28 de enero de 2016, Deepmind emitió un papel pesado, introdujo este golpe el Campeonato Europeo de ajedrez del fan Hui programa de inteligencia artificial.
En mayo de este año, la puntuación de 3:0 para ganar el jugador chino Kija, AlphaGo anunció su jubilación, pero DeepMind no detuvo el ritmo de la investigación. Hora local de Londres el 18 de octubre, el equipo de DeepMind anunció la versión más fuerte de AlphaGo, en código AlphaGo cero. sus tramposos únicos, es "autodidacta". Por otra parte, desde el principio de un libro blanco, cero basado en el aprendizaje, en sólo 3 días, convirtiéndose en el maestro superior.
El equipo dijo, antes de que AlphaGo Zero haya superado el nivel de todas las versiones de AlphaGo. han ganado contra los jugadores surcoreanos versión de Li Shishi de AlphaGo, AlphaGo Zero 100:0 ha alcanzado el éxito abrumador. El equipo de DeepMind investigará sobre AlphaGo Zero en forma de papel, publicado en el 18 de octubre "Nature Journal.
"dentro de dos años AlphaGo alcanzó asombroso." Ahora, AlphaGo Zero es nuestra versión más fuerte, que aumenta mucho. Cero para mejorar la eficacia computacional, y no usar ningún dato del ajedrez humano, "el padre del AlphaGo, co-fundador y CEO de DeepMind Demes ha SABIS (Demis Hassabis) dijo," al final, queremos usarlo el algoritmo de avance, para ayudar a resolver el mundo real problemas urgentes, como el plegamiento de la proteína o el diseño de nuevos materiales. "si nos AlphaGo, podemos progresar en estos temas, tiene el potencial de promover la comprensión de la vida, y de una manera positiva de afectar nuestras vidas"
No más limitado por el conocimiento humano, solamente 4 TPU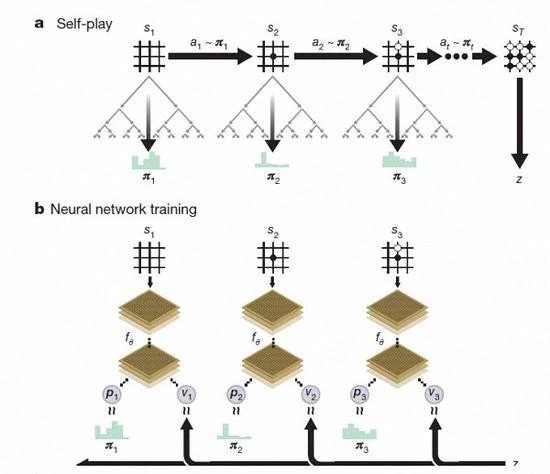
AlphaGo la versión anterior, con millones de expertos humanos ir al ajedrez, y fortalecer la supervisión del aprendizaje de la autoformación.
Antes de derrotar al jugador profesional del Go, pasó meses de entrenamiento, confiando en múltiples máquinas y 48 TPU (Google chips diseñado para acelerar la informática de redes neuronales profundas)
AlphaGo Zero es una mejora cualitativa sobre esta base. La mayor diferencia es que ya no es necesario para los datos humanos. Es decir, no tiene contacto con el ajedrez humano. El equipo de R & D apenas lo dejó libre jugar ajedrez en el tablero, y entonces el juego del uno mismo. Vale la pena mencionar que AlphaGo Zero es un "bajo carbono", para utilizar una máquina y 4 TPU, ahorra mucho recursos.
AlphaGo cero refuerzo aprendizaje bajo el juego del uno mismo ajedrez
Después de unos días de entrenamiento, AlphaGo Zero completó casi 5 millones disco Self Game, puede ir más allá de lo humano, y derrotó a todas las versiones anteriores del AlphaGo. el equipo de DeepMind dijo en el blog oficial, con la red neuronal actualizada y algoritmos de búsqueda de cero recombinante, a medida que el entrenamiento profundiza, el rendimiento del sistema un poco en el progreso de sí mismo. Los resultados del juego están mejorando y mejor, al mismo tiempo, la red neuronal es más precisa.
Además de las diferencias antedichas, AlphaGo cero en 3 aspectos comparados con la versión anterior tiene diferencia obvia
El eje de tiempo de entrenamiento de AlphaGo-Zero
En primer lugar, AlphaGo Zero sólo utiliza blanco y negro en el tablero de ajedrez como entrada, mientras que el primero incluye un pequeño número de características de diseño artificial de entradas
En segundo lugar, AlphaGo Zero utiliza sólo una red neuronal única. En versiones anteriores, el AlphaGo utiliza la estrategia de "red" para elegir el siguiente movimiento, y el uso de "Value Network" para pronosticar cada paso después del ganador. Pero en la nueva versión, la red neuronal dos se puede hacer una. Puede conseguir el entrenamiento y la evaluación más eficientes.
Tercero, AlphaGo Zero no utiliza el método de caminar rápido y aleatorio. En versiones anteriores, AlphaGo es el método de caminar rápido para predecir qué jugador del juego va a ganar el juego de la situación actual. Por el contrario, la nueva versión es depender de la alta calidad de la red neuronal para evaluar la situación del juego.
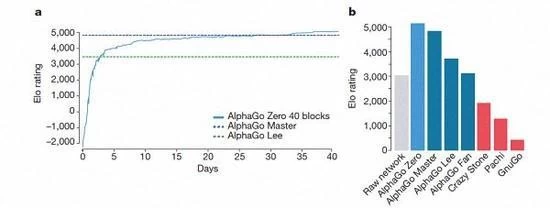
AlphaGo varias versiones de los rankings
De acuerdo con Kazajstán Vizcaya y Silva Introduction, estas diferentes versiones de ayuda de AlphaGo han mejorado en el sistema, y el cambio del algoritmo hace que el sistema se vuelva más fuerte y más eficaz.
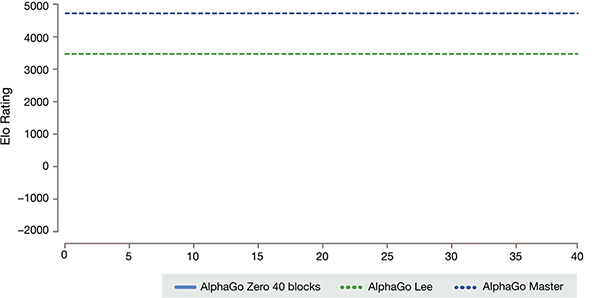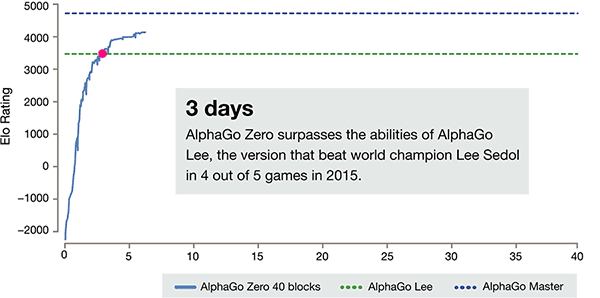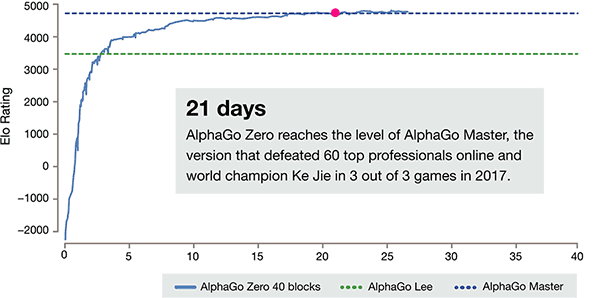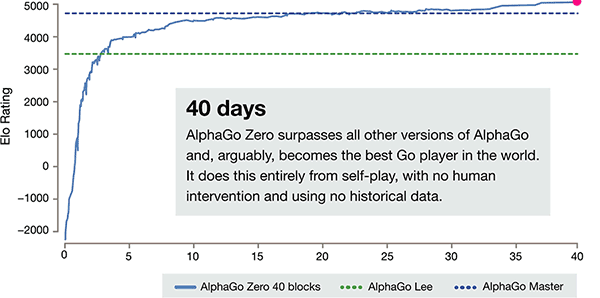
Después de apenas 3 días de entrenamiento del uno mismo, AlphaGo cero en los golpes fuertes la victoria anterior sobre Li Shishi en la vieja versión de AlphaGo, son 100:0. Después de 40 días de autoaprendizaje, AlphaGo Zero venció la versión maestra de AlphaGo. "maestro" venció a los mejores jugadores del mundo, incluso incluyendo Kija ocupó el primer lugar en el mundo.
Para promover el progreso de la sociedad humana usando la inteligencia artificial DeepMind misión, el último AlphaGo no fue, su objetivo ha sido utilizar AlphaGo para crear un general, explorar las herramientas definitivas del universo de. La ascensión de AlphaGo Zero, deja que DeepMind vea un cambio en el destino de la humanidad usando el avance de la tecnología de inteligencia artificial. Actualmente están activos y las instituciones médicas británicas y la cooperación del sector de energía eléctrica, mejoran la eficacia del tratamiento y la eficiencia energética.
Hace más de un año, AlphaGo es un artículo de portada en el período 28 de enero de 2016, Deepmind emitió un papel pesado, introdujo este golpe el Campeonato Europeo de ajedrez del fan Hui programa de inteligencia artificial.
En mayo de este año, la puntuación de 3:0 para ganar el jugador chino Kija, AlphaGo anunció su jubilación, pero DeepMind no detuvo el ritmo de la investigación. Hora local de Londres el 18 de octubre, el equipo de DeepMind anunció la versión más fuerte de AlphaGo, en código AlphaGo cero. sus tramposos únicos, es "autodidacta". Por otra parte, desde el principio de un libro blanco, cero basado en el aprendizaje, en sólo 3 días, convirtiéndose en el maestro superior.
El equipo dijo, antes de que AlphaGo Zero haya superado el nivel de todas las versiones de AlphaGo. han ganado contra los jugadores surcoreanos versión de Li Shishi de AlphaGo, AlphaGo Zero 100:0 ha alcanzado el éxito abrumador. El equipo de DeepMind investigará sobre AlphaGo Zero en forma de papel, publicado en el 18 de octubre "Nature Journal.
"dentro de dos años AlphaGo alcanzó asombroso." Ahora, AlphaGo Zero es nuestra versión más fuerte, que aumenta mucho. Cero para mejorar la eficacia computacional, y no usar ningún dato del ajedrez humano, "el padre del AlphaGo, co-fundador y CEO de DeepMind Demes ha SABIS (Demis Hassabis) dijo," al final, queremos usarlo el algoritmo de avance, para ayudar a resolver el mundo real problemas urgentes, como el plegamiento de la proteína o el diseño de nuevos materiales. "si nos AlphaGo, podemos progresar en estos temas, tiene el potencial de promover la comprensión de la vida, y de una manera positiva de afectar nuestras vidas"
No más limitado por el conocimiento humano, solamente 4 TPU
AlphaGo la versión anterior, con millones de expertos humanos ir al ajedrez, y fortalecer la supervisión del aprendizaje de la autoformación.
Antes de derrotar al jugador profesional del Go, pasó meses de entrenamiento, confiando en múltiples máquinas y 48 TPU (Google chips diseñado para acelerar la informática de redes neuronales profundas)
AlphaGo Zero es una mejora cualitativa sobre esta base. La mayor diferencia es que ya no es necesario para los datos humanos. Es decir, no tiene contacto con el ajedrez humano. El equipo de R & D apenas lo dejó libre jugar ajedrez en el tablero, y entonces el juego del uno mismo. Vale la pena mencionar que AlphaGo Zero es un "bajo carbono", para utilizar una máquina y 4 TPU, ahorra mucho recursos.
AlphaGo cero refuerzo aprendizaje bajo el juego del uno mismo ajedrez
Después de unos días de entrenamiento, AlphaGo Zero completó casi 5 millones disco Self Game, puede ir más allá de lo humano, y derrotó a todas las versiones anteriores del AlphaGo. el equipo de DeepMind dijo en el blog oficial, con la red neuronal actualizada y algoritmos de búsqueda de cero recombinante, a medida que el entrenamiento profundiza, el rendimiento del sistema un poco en el progreso de sí mismo. Los resultados del juego están mejorando y mejor, al mismo tiempo, la red neuronal es más precisa.
El proceso de adquisición de conocimiento por AlphaGo Zero
"la razón por la cual estos detalles técnicos son más fuertes que la versión anterior, ya no tenemos los límites del conocimiento humano, puede aprender a AlphaGo a sus jugadores más altos a ir al campo". El líder del equipo de AlphaGo, David Silva (Dave astilla) dijo.
Según David Silva introducción, AlphaGo Zero utiliza el nuevo método de aprendizaje de refuerzo, hágase el maestro. Ni siquiera sé lo que es un sistema para ir, sólo desde una sola red neuronal, el algoritmo de búsqueda de redes neurales es poderoso, el auto jugando al ajedrez.
Con el aumento del juego del uno mismo, la red neuronal se ajusta gradualmente, realza la capacidad predictiva del paso siguiente, y finalmente gana el juego. Más potente, con una formación en profundidad, el equipo de DeepMind encontró que AlphaGo Zero también descubrió de forma independiente las reglas del juego, y de la nueva estrategia, traer nuevas ideas sobre este juego de ajedrez antiguo ronda.
Estudio de uno mismo durante 3 días, batir la versión antigua de AlphaGo
"la razón por la cual estos detalles técnicos son más fuertes que la versión anterior, ya no tenemos los límites del conocimiento humano, puede aprender a AlphaGo a sus jugadores más altos a ir al campo". El líder del equipo de AlphaGo, David Silva (Dave astilla) dijo.
Según David Silva introducción, AlphaGo Zero utiliza el nuevo método de aprendizaje de refuerzo, hágase el maestro. Ni siquiera sé lo que es un sistema para ir, sólo desde una sola red neuronal, el algoritmo de búsqueda de redes neurales es poderoso, el auto jugando al ajedrez.
Con el aumento del juego del uno mismo, la red neuronal se ajusta gradualmente, realza la capacidad predictiva del paso siguiente, y finalmente gana el juego. Más potente, con una formación en profundidad, el equipo de DeepMind encontró que AlphaGo Zero también descubrió de forma independiente las reglas del juego, y de la nueva estrategia, traer nuevas ideas sobre este juego de ajedrez antiguo ronda.
Estudio de uno mismo durante 3 días, batir la versión antigua de AlphaGo
Además de las diferencias antedichas, AlphaGo cero en 3 aspectos comparados con la versión anterior tiene diferencia obvia
El eje de tiempo de entrenamiento de AlphaGo-Zero
En primer lugar, AlphaGo Zero sólo utiliza blanco y negro en el tablero de ajedrez como entrada, mientras que el primero incluye un pequeño número de características de diseño artificial de entradas
En segundo lugar, AlphaGo Zero utiliza sólo una red neuronal única. En versiones anteriores, el AlphaGo utiliza la estrategia de "red" para elegir el siguiente movimiento, y el uso de "Value Network" para pronosticar cada paso después del ganador. Pero en la nueva versión, la red neuronal dos se puede hacer una. Puede conseguir el entrenamiento y la evaluación más eficientes.
Tercero, AlphaGo Zero no utiliza el método de caminar rápido y aleatorio. En versiones anteriores, AlphaGo es el método de caminar rápido para predecir qué jugador del juego va a ganar el juego de la situación actual. Por el contrario, la nueva versión es depender de la alta calidad de la red neuronal para evaluar la situación del juego.
AlphaGo varias versiones de los rankings
De acuerdo con Kazajstán Vizcaya y Silva Introduction, estas diferentes versiones de ayuda de AlphaGo han mejorado en el sistema, y el cambio del algoritmo hace que el sistema se vuelva más fuerte y más eficaz.
Después de apenas 3 días de entrenamiento del uno mismo, AlphaGo cero en los golpes fuertes la victoria anterior sobre Li Shishi en la vieja versión de AlphaGo, son 100:0. Después de 40 días de autoaprendizaje, AlphaGo Zero venció la versión maestra de AlphaGo. "maestro" venció a los mejores jugadores del mundo, incluso incluyendo Kija ocupó el primer lugar en el mundo.
Para promover el progreso de la sociedad humana usando la inteligencia artificial DeepMind misión, el último AlphaGo no fue, su objetivo ha sido utilizar AlphaGo para crear un general, explorar las herramientas definitivas del universo de. La ascensión de AlphaGo Zero, deja que DeepMind vea un cambio en el destino de la humanidad usando el avance de la tecnología de inteligencia artificial. Actualmente están activos y las instituciones médicas británicas y la cooperación del sector de energía eléctrica, mejoran la eficacia del tratamiento y la eficiencia energética.