























Alpha "Zero" özerk öğrenme üç gün için, insan Milenyum daha fazla, Google ne yapmak için k
chinatopwin
chinatopwin
2017-10-20 09:28:22
19 Ekim 'de Pekin saati, Google 'ın yapay zeka şirketi DeepMind dünyanın en iyi bilim dergisi doğada AlphaGo yeni ilerleme duyurdu, kendini öğrenme durumunda insan müdahale yokluğunda, kendini öğrenme yeni AlphaGoZero sonra 3 gün, 100 ile ilk nesil AlphaGo üzerinden 0 sonuçlar.

AlphaGo Zero resimleri Web gelen
Self öğrenme yeteneği, yapay zeka ve makine öğrenimi için, yeni bir atılım olduğunu. "Geçmişte, insanlar genellikle makine öğreniminin büyük verilere dayalı olduğunu düşünüyor, ama AlphaGoZero 'dan, algoritmanın veriden daha önemli olduğunu bulduk." David Silva AlphaGo projesi (David Silver) için esas olarak sorumludur dedi.
Daha fazla algoritma ve daha az veri kullanımı nedeniyle, AlphaGoZero sadece bir bilgisayar makinesi ve 4 TPU kullanır ve onun Beat Generation AlphaGo birden fazla makine ve 48 TPU kullanır.
Insanlar AlphaGoZero alanda Tanrı düzeyinde gitmek şaşırttı, DeepMind ekibi için, bu sadece başlangıç, onların amacı otonom öğrenme yeteneği yetiştirilmesi, diğer alanlarda daha fazla çözmek için zor bir sorunu çözebilir.
AlphaGo 'den AlphaGo sıfıra AlphaGoMaster
AlphaGo 2015 Ekim ayında mevcut, tanınmış ve satranç oyuncusu li Shishi önce, Avrupa Satranç Şampiyonası mağlup oldu. Dedi fan fan hui hui "zamanında finansal gazeteciler kabul >, onun görüşünde, işgal oyuncusu yenmek için bir program imkansız.
AlphaGo için 0-5 kaybetti, ama o da DeepMind ekibi katıldı, AlphaGo eğitmeye yardımcı oldu. 2015 Mart ayında, o 4-1 için insan top oyuncuları li Shishi. 2017 ' de eğitim başında AlphaGo AlphaGo, "Master", Challenge 60 insan ağdaki oyuncular, yenilmez puanı. 2017 Mayıs ayında, Wuzhen yılında, ana ikinci nesil AlphaGo 3-0 en güçlü insan oyuncular kırmızı yenmek için çağırdı.

Ağdan AlphaGo Çin satranç oyuncusu Jie Jie resimleri
Mayıs ayında bu yıl oyun sırasında, yöneticilerin bir dizi DeepMind için olmuştur < > Mali muhabirler, Master kendini öğrenme yeteneğini fark etti, ve hatta kendi "sezgi", "biz bulduk AlphaGo insan antrenörü itimat gerekmez." David Silva mali muhabire söyledi. < >
Satranç ve kırmızı AlphaGo içinde insan oyuncuların bir çok altında olmuştur yol hayal couldn 't, kırmızı oyun sonra, AlphaGo ilk nesil kusurları bulabilir, Master "Tanrı" atılım elde etti.
AlphaGoZero "bağımsız" daha, eğitim sürecinde, kendi kendine eğitim oyunudur. Şekilde bir başlangıç olarak görülebilir satranç aşina değil, oyuncular düzeyi çok zayıf, ama zaman ilerledikçe, 4.900.000 sonra her oyun için sadece 3 gün içinde, daha güçlü, satranç seviyesi atılım gerçekleştirmek.
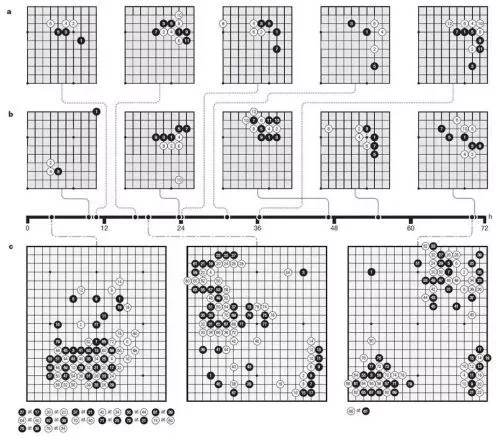
(grafik: 72 saat Atlas AlphaGo eğitim)
İnsan top oyuncusu ke Jie bir go deha olarak kabul edilir, 6 yaşında satranç öğrenmeye başladı, dünya 'da 17 yaşında ilk sırada, ilk insan deha öğrenme on yıl daha fazla, AlphaZero 3 gün ötesine gitmek oldu
Ama DeepMind ekibi burada değil, "AlphaGo anlamı insanların yenmek için değil, daha fazla sorun çözmek için bilgi anlamak için değil." David Silva dedi
Ticari ivme: 1/4 enerji ticari gerçekleştirilmesi için
Bu yıl Mayıs ayında, DeepMind kurucusu Hassabis Maliye muhabiri ile röportajda şöyle dedi: "Google bir roket ise, DeepMind yakıt."
Bu konumlandırma altında, her ne kadar AlphaGo hızla gelişti, weiqi üzerinde durmak asla
AlphaGo Zero resimleri Web gelen
Self öğrenme yeteneği, yapay zeka ve makine öğrenimi için, yeni bir atılım olduğunu. "Geçmişte, insanlar genellikle makine öğreniminin büyük verilere dayalı olduğunu düşünüyor, ama AlphaGoZero 'dan, algoritmanın veriden daha önemli olduğunu bulduk." David Silva AlphaGo projesi (David Silver) için esas olarak sorumludur dedi.
Daha fazla algoritma ve daha az veri kullanımı nedeniyle, AlphaGoZero sadece bir bilgisayar makinesi ve 4 TPU kullanır ve onun Beat Generation AlphaGo birden fazla makine ve 48 TPU kullanır.
Insanlar AlphaGoZero alanda Tanrı düzeyinde gitmek şaşırttı, DeepMind ekibi için, bu sadece başlangıç, onların amacı otonom öğrenme yeteneği yetiştirilmesi, diğer alanlarda daha fazla çözmek için zor bir sorunu çözebilir.
AlphaGo 'den AlphaGo sıfıra AlphaGoMaster
AlphaGo 2015 Ekim ayında mevcut, tanınmış ve satranç oyuncusu li Shishi önce, Avrupa Satranç Şampiyonası mağlup oldu. Dedi fan fan hui hui "zamanında finansal gazeteciler kabul >, onun görüşünde, işgal oyuncusu yenmek için bir program imkansız.
AlphaGo için 0-5 kaybetti, ama o da DeepMind ekibi katıldı, AlphaGo eğitmeye yardımcı oldu. 2015 Mart ayında, o 4-1 için insan top oyuncuları li Shishi. 2017 ' de eğitim başında AlphaGo AlphaGo, "Master", Challenge 60 insan ağdaki oyuncular, yenilmez puanı. 2017 Mayıs ayında, Wuzhen yılında, ana ikinci nesil AlphaGo 3-0 en güçlü insan oyuncular kırmızı yenmek için çağırdı.
Ağdan AlphaGo Çin satranç oyuncusu Jie Jie resimleri
Mayıs ayında bu yıl oyun sırasında, yöneticilerin bir dizi DeepMind için olmuştur < > Mali muhabirler, Master kendini öğrenme yeteneğini fark etti, ve hatta kendi "sezgi", "biz bulduk AlphaGo insan antrenörü itimat gerekmez." David Silva mali muhabire söyledi. < >
Satranç ve kırmızı AlphaGo içinde insan oyuncuların bir çok altında olmuştur yol hayal couldn 't, kırmızı oyun sonra, AlphaGo ilk nesil kusurları bulabilir, Master "Tanrı" atılım elde etti.
AlphaGoZero "bağımsız" daha, eğitim sürecinde, kendi kendine eğitim oyunudur. Şekilde bir başlangıç olarak görülebilir satranç aşina değil, oyuncular düzeyi çok zayıf, ama zaman ilerledikçe, 4.900.000 sonra her oyun için sadece 3 gün içinde, daha güçlü, satranç seviyesi atılım gerçekleştirmek.
(grafik: 72 saat Atlas AlphaGo eğitim)
İnsan top oyuncusu ke Jie bir go deha olarak kabul edilir, 6 yaşında satranç öğrenmeye başladı, dünya 'da 17 yaşında ilk sırada, ilk insan deha öğrenme on yıl daha fazla, AlphaZero 3 gün ötesine gitmek oldu
Ama DeepMind ekibi burada değil, "AlphaGo anlamı insanların yenmek için değil, daha fazla sorun çözmek için bilgi anlamak için değil." David Silva dedi
Ticari ivme: 1/4 enerji ticari gerçekleştirilmesi için
Bu yıl Mayıs ayında, DeepMind kurucusu Hassabis Maliye muhabiri ile röportajda şöyle dedi: "Google bir roket ise, DeepMind yakıt."
Bu konumlandırma altında, her ne kadar AlphaGo hızla gelişti, weiqi üzerinde durmak asla