























阿尔法去 "零" 自主学习三天, 比人类一千年多了, Google 用它做什么呢?
chinatopwin
chinatopwin
2017-10-20 09:28:22
北京时间10月19日上午, 谷歌的人工智能公司 DeepMind 宣布了 AlphaGo 在世界顶尖科学杂志《自然》中的新进展, 可以在没有人类干预的情况下自我学习, 在新AlphaGoZero 在3天以后, 与100比0结果在第一代 AlphaGo。

AlphaGo 零图片来自网络
自主学习能力, 对于人工智能和机器学习来说, 是一个新的突破。"过去, 人们普遍认为机器学习是基于大量的数据, 但是从 AlphaGoZero, 我们发现算法比数据更重要。大卫·席尔瓦主要负责 AlphaGo 项目 (david 西尔弗) 说。
由于使用了更多的算法和较少的数据, AlphaGoZero 只使用一个计算机器和 4 tpu, 其节拍一代 AlphaGo 使用多台机器和 48 tpu。
当人们惊讶于 AlphaGoZero 在田野上走到上帝的层面, 对于 DeepMind 团队来说, 这仅仅是开始, 他们的目的是培养自主学习的能力, 解决更多的其他领域无法解决的难题。
从 AlphaGo, AlphaGoMaster 到 AlphaGo 零
AlphaGo 在2015年10月可利用, 在著名和棋球员李石狮之前, 它击败了欧洲棋冠军。范徐丽泰表示, "接受财经记者在当时的 >, 在他看来, 一个方案, 以击败职业球员是不可能的。
他输给了 AlphaGo 0-5, 但他也加入了 DeepMind 队, 帮助训练 AlphaGo. 2016 在 3月, 当他帮助了4-1 击败了人的顶尖球员李石狮. 2017 在训练开始在假名之下 AlphaGo AlphaGo "大师" 挑战60人在网络上的玩家, 不败得分. 2017 在 5月, 在乌镇, 被称为第二代大师 AlphaGo 3-0 击败最强的人类球员 kija。

AlphaGo 中国象棋选手杰杰网络图片
在今年5月的比赛中, 一些高管一直在 DeepMind < > 财经记者, 掌握了自己的自我学习能力, 甚至有自己的 "直觉", "我们发现 AlphaGo 不需要依赖于人的训练。戴维. 席尔瓦告诉金融记者。< >
象棋和 kija 在 AlphaGo 已经下了很多人无法想象的方式, kija 说在比赛后, 第一代的 AlphaGo 可以找到瑕疵, 师父已经实现了 "神" 的飞跃。
AlphaGoZero 在 "独立" 的进一步训练过程中, 是自我训练的游戏。从图中可以看出, 一开始不熟悉下棋, 球员水平很弱, 但随着时间的推移, 在短短3天的每场比赛后 400万900的局, 越来越强, 实现象棋水平的突破。
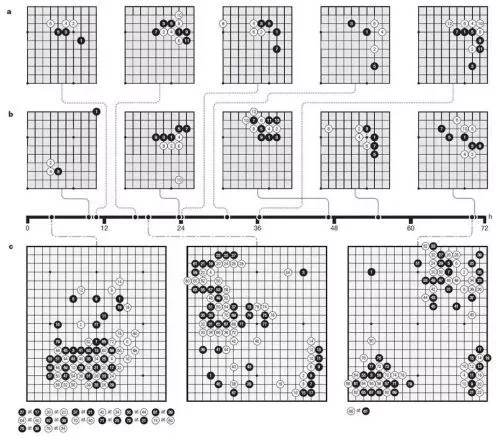
(图:72 小时 AlphaGo 训练地图集)
人类顶尖选手柯杰被认为是一个围棋天才, 6 岁开始学习象棋, 在17岁的世界排名第一, 第一个人类天才超过十年的学习, AlphaZero 是3天超越
但 DeepMind 团队不是在这里, "AlphaGo 的意义不是打败人, 而是为了了解知识, 解决更多的问题。大卫·席尔瓦说
商业加速度: 1/4 能量为商业实现
今年 5月, DeepMind 创始人 Jamis 哈萨比斯在接受金融记者采访时表示: "如果谷歌是火箭, DeepMind 就是燃料。
在这种定位下, 虽然 AlphaGo 发展迅速, 但它永远不会停止在围棋
AlphaGo 零图片来自网络
自主学习能力, 对于人工智能和机器学习来说, 是一个新的突破。"过去, 人们普遍认为机器学习是基于大量的数据, 但是从 AlphaGoZero, 我们发现算法比数据更重要。大卫·席尔瓦主要负责 AlphaGo 项目 (david 西尔弗) 说。
由于使用了更多的算法和较少的数据, AlphaGoZero 只使用一个计算机器和 4 tpu, 其节拍一代 AlphaGo 使用多台机器和 48 tpu。
当人们惊讶于 AlphaGoZero 在田野上走到上帝的层面, 对于 DeepMind 团队来说, 这仅仅是开始, 他们的目的是培养自主学习的能力, 解决更多的其他领域无法解决的难题。
从 AlphaGo, AlphaGoMaster 到 AlphaGo 零
AlphaGo 在2015年10月可利用, 在著名和棋球员李石狮之前, 它击败了欧洲棋冠军。范徐丽泰表示, "接受财经记者在当时的 >, 在他看来, 一个方案, 以击败职业球员是不可能的。
他输给了 AlphaGo 0-5, 但他也加入了 DeepMind 队, 帮助训练 AlphaGo. 2016 在 3月, 当他帮助了4-1 击败了人的顶尖球员李石狮. 2017 在训练开始在假名之下 AlphaGo AlphaGo "大师" 挑战60人在网络上的玩家, 不败得分. 2017 在 5月, 在乌镇, 被称为第二代大师 AlphaGo 3-0 击败最强的人类球员 kija。
AlphaGo 中国象棋选手杰杰网络图片
在今年5月的比赛中, 一些高管一直在 DeepMind < > 财经记者, 掌握了自己的自我学习能力, 甚至有自己的 "直觉", "我们发现 AlphaGo 不需要依赖于人的训练。戴维. 席尔瓦告诉金融记者。< >
象棋和 kija 在 AlphaGo 已经下了很多人无法想象的方式, kija 说在比赛后, 第一代的 AlphaGo 可以找到瑕疵, 师父已经实现了 "神" 的飞跃。
AlphaGoZero 在 "独立" 的进一步训练过程中, 是自我训练的游戏。从图中可以看出, 一开始不熟悉下棋, 球员水平很弱, 但随着时间的推移, 在短短3天的每场比赛后 400万900的局, 越来越强, 实现象棋水平的突破。
(图:72 小时 AlphaGo 训练地图集)
人类顶尖选手柯杰被认为是一个围棋天才, 6 岁开始学习象棋, 在17岁的世界排名第一, 第一个人类天才超过十年的学习, AlphaZero 是3天超越
但 DeepMind 团队不是在这里, "AlphaGo 的意义不是打败人, 而是为了了解知识, 解决更多的问题。大卫·席尔瓦说
商业加速度: 1/4 能量为商业实现
今年 5月, DeepMind 创始人 Jamis 哈萨比斯在接受金融记者采访时表示: "如果谷歌是火箭, DeepMind 就是燃料。
在这种定位下, 虽然 AlphaGo 发展迅速, 但它永远不会停止在围棋